[論文レビュー] In-Context Learning for Extreme Multi-Label Classification
論文は Infer--Retrieve--Rank を提案する。これは frozen retriever と 2 つの in-context LM モジュールを組み合わせ、fine-tuning なしで極端なマルチラベル分類 XMC に取り組むモジュラーな in-context 学習プログラムで、いくつかのベンチマークで最先端の結果を達成する。最適化は DSPy を用いて、ほんの数十のラベル付き例のみでプロンプトをブートストラップする。
Multi-label classification problems with thousands of classes are hard to solve with in-context learning alone, as language models (LMs) might lack prior knowledge about the precise classes or how to assign them, and it is generally infeasible to demonstrate every class in a prompt. We propose a general program, $\texttt{Infer--Retrieve--Rank}$, that defines multi-step interactions between LMs and retrievers to efficiently tackle such problems. We implement this program using the $\texttt{DSPy}$ programming model, which specifies in-context systems in a declarative manner, and use $\texttt{DSPy}$ optimizers to tune it towards specific datasets by bootstrapping only tens of few-shot examples. Our primary extreme classification program, optimized separately for each task, attains state-of-the-art results across three benchmarks (HOUSE, TECH, TECHWOLF). We apply the same program to a benchmark with vastly different characteristics and attain competitive performance as well (BioDEX). Unlike prior work, our proposed solution requires no finetuning, is easily applicable to new tasks, alleviates prompt engineering, and requires only tens of labeled examples. Our code is public at https://github.com/KarelDO/xmc.dspy.
研究の動機と目的
- インコヒーレント学習だけを用いた場合に、数千クラスを持つ極端なマルチラベル分類(XMC) の課題に対処する。
- 凍結コンポーネントと最小限の監視を活用して高い性能を達成する、モジュラーなパイプライン(Infer--Retrieve--Rank)を提案する。
- DSPy プログラミングモデルを用いてプロンプトのブートストラッピングと最適化を自動化し、ファインチューニングなしでさまざまなデータセットに適応する。
- 複数の XMC ベンチマーク(HOUSE, TECH, TECHWOLF, BioDEX)で有効性を示し、コスト効率の高いデプロイを実証する。
提案手法
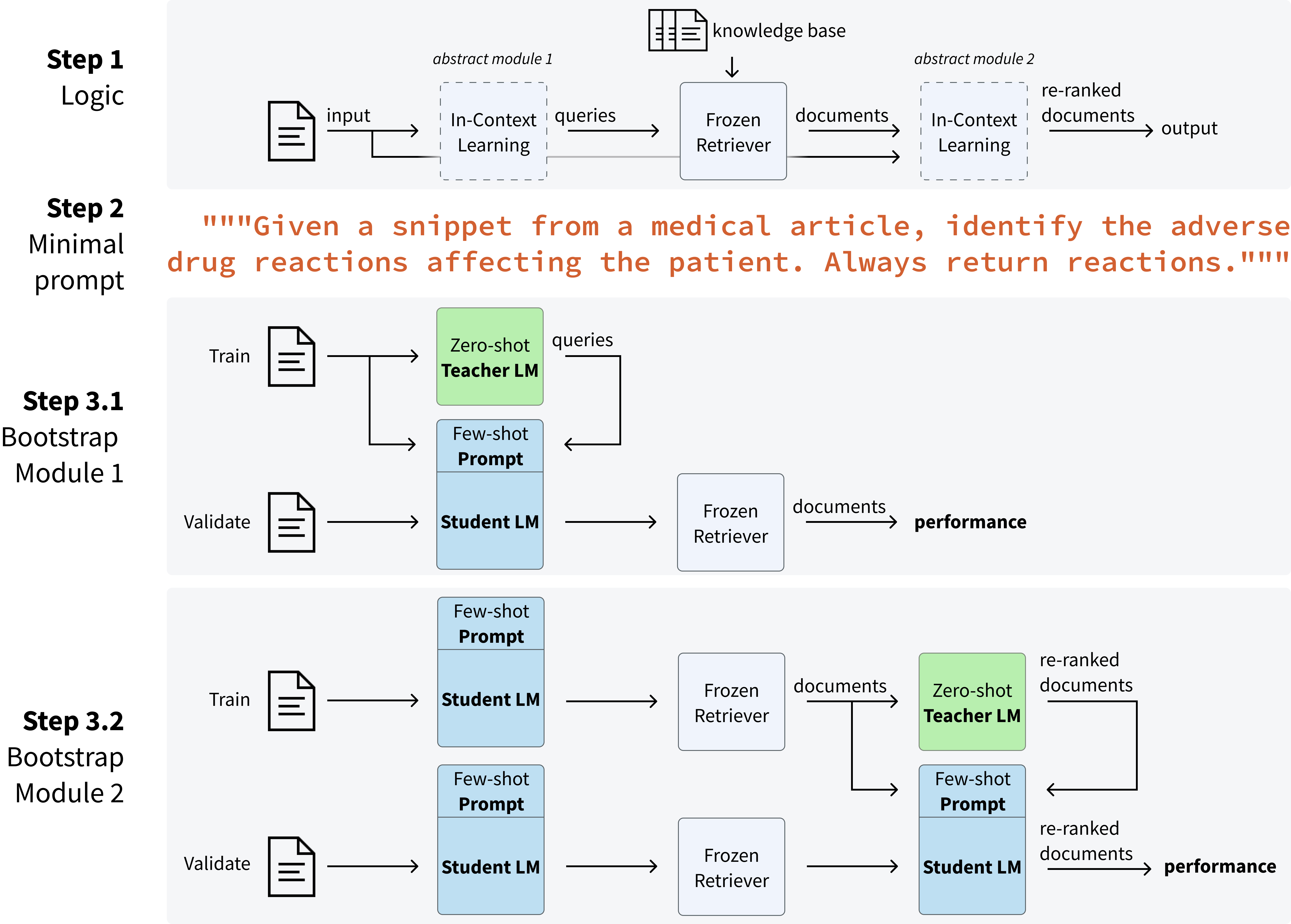
- Infer--Retrieve--Rank (IReRa) を導入する。3段階のプログラム: Infer(入力から関連ラベルクエリを予測するLM)、Retrieve(凍結リトリーバーがクエリ類似度でラベルをランク付け)、Rank(LM が取得済みラベルを再ランク付け) 。
- DSPyフレームワークを用いてモジュールを宣言的に指定し、ブートストラップされた少数ショットプロンプトでタスクごとに最適化する。
- 2つのLMコンポーネントの少数ショットプロンプトをブーストするためのゼロショット教師LMを使用し、最適化はタスクあたり約50のラベル付き検証例と約20の教師呼び出し+1,500の学生LM呼び出しに依存する。
- Infer を Llama-2-7b-chat(student)と GPT-3.5(teacher)でインスタンス化する。Rank は GPT-4、Retrieve は凍結済みの all-mpnet-base-v2/BioLORD風リトリーバーで。
- 各データセットごとに、各モジュール(Infer/Rank)のインコヒーレントな挙動と最小限のゼロショットプロンプトを定義するシードプロンプトを提供し、DSPy がブートストラッピングとラベルの選択を処理する。
- 4データセットにわたりRP@5とRP@10の指標を評価し、従来のベースラインおよびファインチューニング済みシステムと比較する。
実験結果
リサーチクエスチョン
- RQ1ファインチューニングなしで、モジュラーなインコヒーレント学習パイプラインは競争力のあるまたは最先端のXMC性能を達成できるか?
- RQ21タスクあたり、 performant IReRa プログラムをブーストするには、どれくらいのラベル付きデータとどれくらいのLM呼び出しが必要か?
- RQ3各モジュール(Infer, Retrieve, Rank)とそれらの最適化がXMC性能に与える影響は?
- RQ4生物医学的データとESCOジョブスキルなど、異なる特性を持つタスク間でアプローチがどのように一般化するか?
主な発見
| データセット | RP@5 | RP@10 |
|---|---|---|
| HOUSE | 56.50 | 65.76 |
| TECH | 59.61 | 70.23 |
| TECHWOLF | 57.04 | 65.17 |
| BioDEX | 24.73 | 27.67 |
- IReRa は HOUSE, TECH, TECHWOLF データセットで、ファインチューニングなしかつ約50のラベル付き検証例で最先端の RP@5 および RP@10 を達成。
- BioDEX では IReRa は有意な進展を示すが、最高のファインチューニング済みシステムには厳密には勝っていない。Rank モジュールを追加する、または Infer をさらに最適化することで結果が改善する。
- 最良のプログラムは Infer--Retrieve--Rank で、1つの凍結リトリーバーと2つのLMモジュールを使用し、ブートストラップにはタスクあたり約20の教師呼び出しと1,500の学生呼び出し、さらに新しい入力ごとに各モジュールあたり約1回のLM呼び出しがかかる。
- 最適化ステップ(Infer、Retrieve、Rank)はそれぞれ性能向上に寄与する。より単純な Infer--Retrieve セットアップでも、単一のLMと凍結リトリーバーで競争力のある結果を得られる。
- ファインチューニング済みシステムと比較して、IReRa はデータ要件を低く抑え、広範なプロンプト設計を回避しつつ、最小限のシードプロンプトとDSPy駆動の最適化で新しいデータセットへ適応可能である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。