[論文レビュー] In or Out? Fixing ImageNet Out-of-Distribution Detection Evaluation
本論文は、多くの ImageNet-1K OOD データセットに ID 汚染が含まれていることを示し、64 の OOD クラスと 5879 枚のクリーンな画像を持つ NINCO(No ImageNet Class Objects)を導入し、アーキテクチャ全体での OOD 検出器を幅広く分析するとともに、事前学習の影響とクラスごとの評価および OOD ユニットテストの必要性を強調しています。
Out-of-distribution (OOD) detection is the problem of identifying inputs which are unrelated to the in-distribution task. The OOD detection performance when the in-distribution (ID) is ImageNet-1K is commonly being tested on a small range of test OOD datasets. We find that most of the currently used test OOD datasets, including datasets from the open set recognition (OSR) literature, have severe issues: In some cases more than 50$\%$ of the dataset contains objects belonging to one of the ID classes. These erroneous samples heavily distort the evaluation of OOD detectors. As a solution, we introduce with NINCO a novel test OOD dataset, each sample checked to be ID free, which with its fine-grained range of OOD classes allows for a detailed analysis of an OOD detector's strengths and failure modes, particularly when paired with a number of synthetic "OOD unit-tests". We provide detailed evaluations across a large set of architectures and OOD detection methods on NINCO and the unit-tests, revealing new insights about model weaknesses and the effects of pretraining on OOD detection performance. We provide code and data at https://github.com/j-cb/NINCO.
研究の動機と目的
- ImageNet-1K OOD テストデータセットにおける ID 汚染を特定・定量化する。
- クリーンで挑戦的な OOD テストセット(NINCO)を、検出器の弱点をより理解するための per-class 評価と共に提案する。
- 異なるアーキテクチャと事前学習 regimes にわたる OOD 検出手法の性能を分析する。
- 自然画像を超える検出器の弱点を探る OOD ユニットテストを導入する。
- 公正な評価と OOD 検出器の報告のための推奨事項を提供する。
提案手法
- 一般に用いられる OOD データセットごとに 400 のランダムサンプルを系統的に manual inspection して ID 汚染を測定する。
- 64 の OOD クラスにわたる 5,879 枚の画像を持つ NINCO を作成し、ID フリーであることを手動検証したほか、17 個の合成 OOD ユニットテストを追加する。
- 複数のアーキテクチャ(ViT、ConvNets)とさまざまな事前学習(IN-21K、CLIP、JFT など)で 11 の OOD 検出手法を評価する。
- MSP ベースライン、特徴量ベースの検出器(Maha、RMaha、ViM)、他の手法(MaxLogit、Energy、KL-Matching、KNN、ReAct など)、前処理前の特徴利用を含む解析を行う。
- 事前学習が OOD 検出性能に与える影響と集計指標 vs. クラス別指標の信頼性を評価する。
実験結果
リサーチクエスチョン
- RQ1既存の ImageNet-1K OOD テストデータセットは、インディストリビューションのオブジェクトでどれだけ汚染されているのか?
- RQ2クリーンで ID-フリーな OOD テストセット(NINCO)は、アーキテクチャを跨いだ OOD 検出器の評価をより信頼できるものにできるのか?
- RQ3事前学習の種類と特徴量の使用が OOD 検出性能に与える影響はどの程度か?
- RQ4自然画像データセットでは露呈しない弱点を、合成 OOD ユニットテストは明らかにするのか?
- RQ5公正な OOD 検出器のベンチマークのために、どの評価慣行(クラスごとの分布、ユニットテスト)を採用すべきか?
主な発見
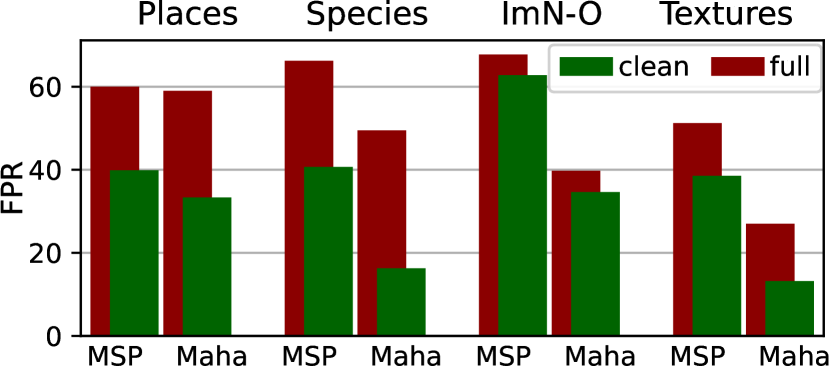
- IN-1K の多くの広く用いられている OOD データセットは ID 汚染を含んでおり、場所によっては 50% を超えることがある(Places や Species など)。
- ID 汚染は強力な検出器を不当に罰する可能性があると同時に、検出器が OOD とみなすべきでない ID 内容を正しく識別してしまい false positives を過大評価することがある。
- NINCO は 64 の手動検証済み OOD クラスと 5,879 枚の ID フリー画像を提供し、検出器の強みと失敗モードの詳細な分析を可能にするとともに、弱点を探る 17 の合成ユニットテストを提供する。
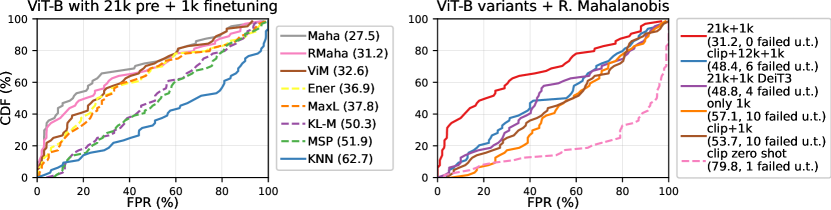
- 大規模データセットでの事前学習は一般に OOD 検出を改善する傾向があり、前処理前特徴ベースの手法は MSP より上回ることが多いが、利得はモデルと事前学習に強く依存する。
- 前処理前特徴を使用した特徴量ベースの検出は、モデル間でより一貫した改善をもたらす傾向があるが、ゼロショット CLIP ベースの手法は NINCO 上で IN-1K 分類器を上回らない。
- 高度な検出器での平均 FPR の改善は、NINCO 上で一部の伝統的ベンチマークよりも顕著であり、クラスごとの解析により OOD クラスごとに性能のばらつきが大きいことが分かる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。