[論文レビュー] Inference with Reference: Lossless Acceleration of Large Language Models
LLMA は参照文書から一致したテキスト span をコピーして自己回帰型 LLM のデコードを加速し、並列検証を可能にし、追加のモデルなしで約 2x–3x のスピードアップを達成します。
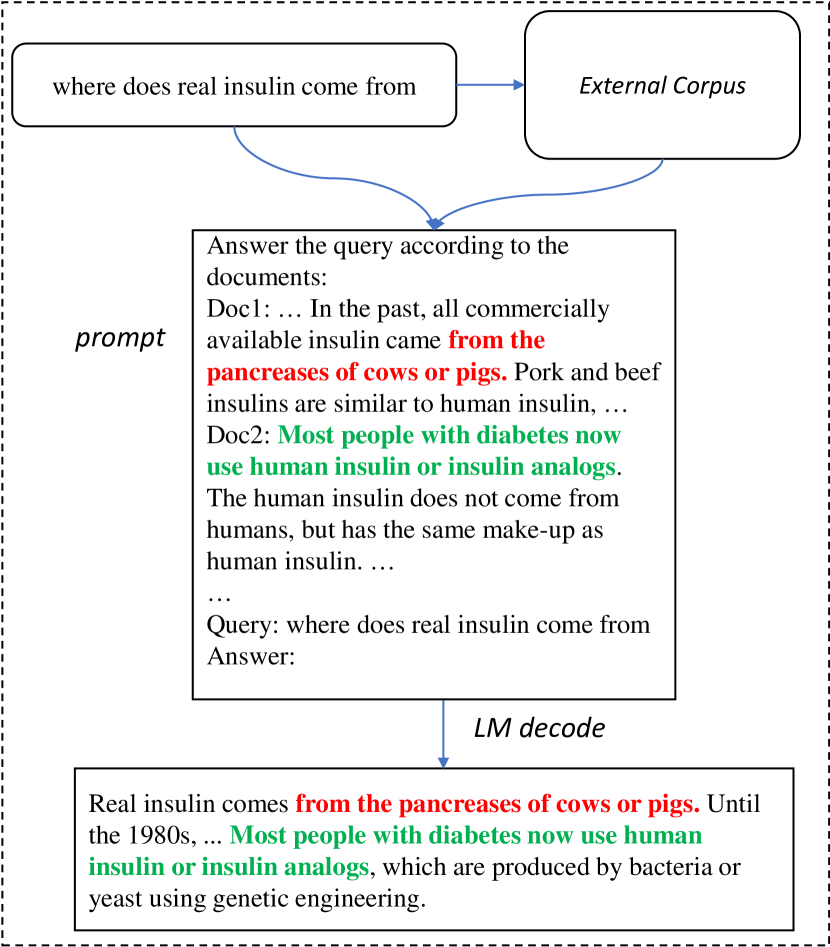
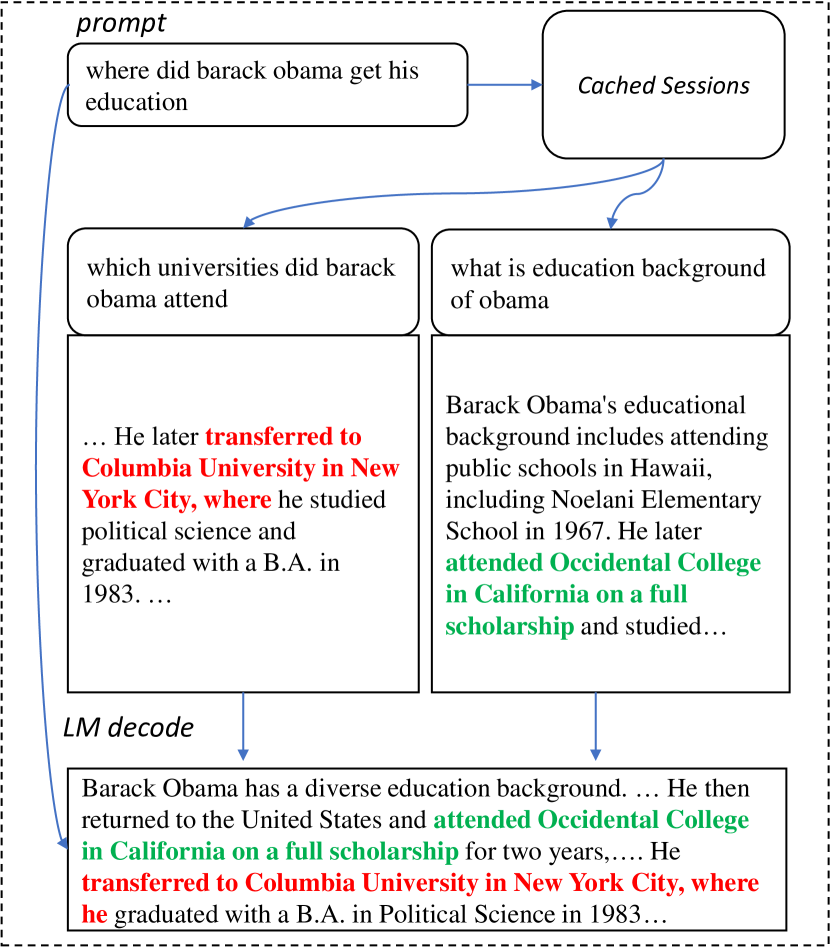
We propose LLMA, an LLM accelerator to losslessly speed up Large Language Model (LLM) inference with references. LLMA is motivated by the observation that there are abundant identical text spans between the decoding result by an LLM and the reference that is available in many real world scenarios (e.g., retrieved documents). LLMA first selects a text span from the reference and copies its tokens to the decoder and then efficiently checks the tokens' appropriateness as the decoding result in parallel within one decoding step. The improved computational parallelism allows LLMA to achieve over 2x speed-up for LLMs with identical generation results as greedy decoding in many practical generation scenarios where significant overlap between in-context reference and outputs exists (e.g., search engines and multi-turn conversations).
研究の動機と目的
- 自己回帰型 LLM の推論コストをモデルの重みを変えずに削減する動機づけ。
- 生成テキストと利用可能な参照文書との重複を活用してデコードを高速化する。
- 同一の貪欲出力を維持する参照ベースのデコード機構を提案する。
- retrieval-augmented generation、キャッシュセッション、そしてマルチターンの対話で実用的なスピードアップを示す。
提案手法
- 参照における一致テキスト span を見つけ、それをトークンとしてデコーダ入力にコピーする LLMA デコoding を導入する。
- 一致が見つかった場合には k トークンの実行を予めコピーし、各トークンをモデルの次トークン確率に対して妥当性検証する。
- トークンごとに検証することで Outputs が vanilla greedy decoding と同一になることを保証する。
- 二つのハイパーパラメータ: match length n と copy length k を用い、コピーのトリガーと程度を制御する。
- 二つのデプロイメントシナリオをサポートする: retrieval-augmented generation および cache-assisted generation(ひいてはマルチターン対話)。
- 訓練や追加のドラフトモデルを用いず、コピーと検証のステップを強化した標準的な自己回帰デコードを実装する。
実験結果
リサーチクエスチョン
- RQ1LLMA はモデルサイズ 7B、13B、30B およびシナリオ(RAG、CAG)全体でどの程度のスピードアップを達成できるか?
- RQ2異なる設定で最適な match length n および copy length k はどのようになるか?
- RQ3LLMA はトークン処理速度と総デコード時間の点でベースラインの greedy デコーダと比較してどうか?
- RQ4LLMA は高速化しつつ従来の greedy デコードと同一の生成結果を保持するか?
主な発見
| モデル | RAG n | RAG k | CAG n | CAG k |
|---|---|---|---|---|
| 7B | 1 | 18 | 1 | 15 |
| 13B | 1 | 14 | 1 | 15 |
| 30B | 1 | 18 | 1 | 18 |
- LLMA は RAG および CAG シナリオで 7B、13B、30B モデルの全てにおいて約 2x–3x のスピードアップを達成する。
- 最適な match length および copy length はモデルとシナリオによって異なり、報告された実験では n は通常 1、k は約 14–18。
- LLMA は コピーされたトークンを受理前に検証することで greedy デコードと同一の出力を維持する。
- スピードアップは並列性の向上とデコードステップの削減によって生じ、特に大きなモデルや k が大きい場合(最大で 15 以上)に顕著。
- GPT-3.5/DaVinci-003 系のプロンプトを用いた実験は、取得済みまたはキャッシュされた参照を使用した実実的な設定で実用的な利得を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。