[論文レビュー] Inference without Interference: Disaggregate LLM Inference for Mixed Downstream Workloads
TetriInfer は prefill と decode フェーズを分離し、チャンク化、二段階スケジューリング、長さ予測を用いて混合 LLM 推論ワークロードの干渉を低減し、TTFT、JCT、効率の大幅な改善を達成するとともに、極端なワークロードでの限界を示しています。
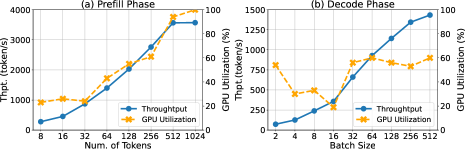
Transformer-based large language model (LLM) inference serving is now the backbone of many cloud services. LLM inference consists of a prefill phase and a decode phase. However, existing LLM deployment practices often overlook the distinct characteristics of these phases, leading to significant interference. To mitigate interference, our insight is to carefully schedule and group inference requests based on their characteristics. We realize this idea in TetriInfer through three pillars. First, it partitions prompts into fixed-size chunks so that the accelerator always runs close to its computationsaturated limit. Second, it disaggregates prefill and decode instances so each can run independently. Finally, it uses a smart two-level scheduling algorithm augmented with predicted resource usage to avoid decode scheduling hotspots. Results show that TetriInfer improves time-to-first-token (TTFT), job completion time (JCT), and inference efficiency in turns of performance per dollar by a large margin, e.g., it uses 38% less resources all the while lowering average TTFT and average JCT by 97% and 47%, respectively.
研究の動機と目的
- prefill と decode フェーズ全体での混合 LLM 推論リクエストにおける干渉を動機づけ、定量化する。
- フェーズ分離とワークロード認識スケジューリングによって干渉を最小化するクラウド規模の推論提供システムを開発する。
- 実用的な実装(TetriInfer)を示し、一般的なワークロードで vanilla vLLM を上回ることを示し、その限界を分析する。
提案手法
- プロンプトを固定サイズのチャンクに分割して、prefill 中にアクセラレータを計算飽和状態に保つ。
- prefill と decode フェーズを分離して、それぞれ独立したインスタンスで実行し、間で KV キャッシュを転送する。
- 長さ予測を備えた二段階スケジューリングシステムを実装して、decode ワークロードを誘導しホットスポットを回避する。
- 生成トークン数を推定するために小さな LLM ベースの長さ予測器を使用し、decode スケジューリングを指示する。
- チャンク化された prefill とディスパッチャを採用して、予測されるリソース使用量に基づいて decode インスタンスをバランスさせる。
- メモリスラッシュを減らすため、作業セットを考慮した decode スケジューリングポリシーを vLLM に拡張する。
![Figure 1: Length Distribution. Prompt Tokens for Prefill and Generated Tokens during Decode. Data sources: conversation [ 35 ] , summarization [ 17 ] , writing [ 18 ] .](https://ar5iv.labs.arxiv.org/html/2401.11181/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1現在のデプロイ実践の下で、混合 LLM の prefill と decode 要求を同時に実行した場合のパフォーマンスはどうなるか?
- RQ2クラウド規模のデプロイメントで、prefill と decode 間、さらには decode 要求間の干渉を分散型 LLM 推論提供システムはどのように最小化できるか?
主な発見
- TetriInfer は vanilla vLLM と比較して、混合ワークロードでの干渉を大幅に減少させ、効率を向上させる。
- 軽い prefill と重い decode ワークロードの場合、TetriInfer は perf/$ を 2.4x 改善する。
- 一般的な混合ワークロードでは、TetriInfer は平均 TTFT を 85%、平均 JCT を 50% 改善する。
- TetriInfer は heavy prefill and heavy decode workloads には理想的ではなく、 gains は限られ、オーバーヘッドが相殺されない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。