[論文レビュー] #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models
InsTag はオープンセットの SFT クエリを自動でタグ付けして指示の多様性と複雑さを定量化し、複雑さに焦点を当てたデータ選択子を用いて TagLM モデルを訓練し、比較的小規模な SFT データで MT-Bench のパフォーマンスを高める。
Foundation language models obtain the instruction-following ability through supervised fine-tuning (SFT). Diversity and complexity are considered critical factors of a successful SFT dataset, while their definitions remain obscure and lack quantitative analyses. In this work, we propose InsTag, an open-set fine-grained tagger, to tag samples within SFT datasets based on semantics and intentions and define instruction diversity and complexity regarding tags. We obtain 6.6K tags to describe comprehensive user queries. Then we analyze popular open-sourced SFT datasets and find that the model ability grows with more diverse and complex data. Based on this observation, we propose a data selector based on InsTag to select 6K diverse and complex samples from open-source datasets and fine-tune models on InsTag-selected data. The resulting models, TagLM, outperform open-source models based on considerably larger SFT data evaluated by MT-Bench, echoing the importance of query diversity and complexity. We open-source InsTag in https://github.com/OFA-Sys/InsTag.
研究の動機と目的
- SFTデータの多様性と複雑さを定量化するための細粒度でオープンセットの指示タグを定義する。
- 高品質なタグを生成するために、ChatGPTと正規化を用いた自動タグ付けパイプラインを開発する。
- オープンソースのSFTデータセットを分析し、多様性と複雑さが整列性能とどのように相関するかを明らかにする。
- InsTag を基にしたデータセレクタを提案し、SFTの多様で複雑なサンプルを厳選する。
- InsTag 選択データでファインチューニングしたモデル(TagLM)が、MT-Bench のいくつかのベースラインを上回ることを示す。
提案手法
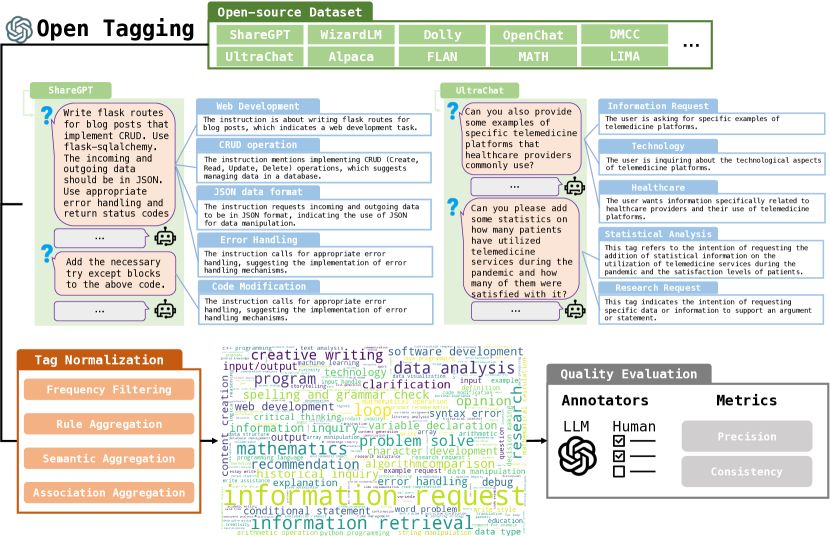
- ChatGPT に対して、クエリをオープンセットの細粒度意図タグで注釈付けするよう促す。
- 頻度フィルタリング、ルールの統合、意味的クラスタリング(DBSCAN)、および関連付けの統合(FP-Growth)によって生のタグを正規化する。
- 精度と一貫性の指標を用いて、GPT-4と人間のアノテータによるタグ付け品質を評価する。
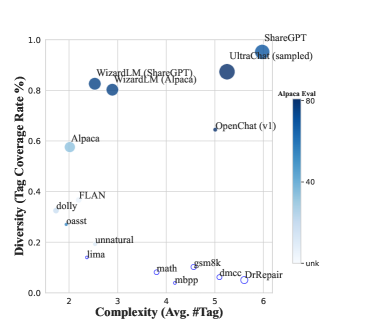
- タグベースの指標(固有タグのカバレッジ、クエリあたりの平均タグ数)を用いてデータセットの多様性と複雑さを分析する。
- Algorithm 1(複雑さ優先の多様性サンプリング)を用いてSFT向けに6Kの高複雑度/多様性クエリをサンプリングする。
- InsTag選択データ上で13B LLaMA/LLaMA-2モデルをファインチューニングし、MT-Benchで評価する。
実験結果
リサーチクエスチョン
- RQ1オープンセットの細粒度指示タグ付けは、SFTデータセットの多様性と複雑さを効果的に定量化できるか。
- RQ2SFTデータの指示多様性と複雑さが、LLMの整列性能の向上と相関するか。
- RQ3InsTagベースのデータ選択は、ベースラインと比較して少量のSFTデータでより高性能なLLMsを生み出せるか。
- RQ4InsTag選択データで訓練したTagLMモデルは、MT-Benchでプロプライエタリおよびオープンソースのベースラインとどう比較されるか。
主な発見
| Model | Data Size | MT-Bench |
|---|---|---|
| gpt-4 | - | 8.99 |
| gpt-3.5-turbo | - | 7.94 |
| claude-v1 | - | 7.90 |
| Llama-2-13b-chat | - | 6.65 |
| TagLM-13b-v2.0 | 6K | 6.55±0.02 |
| alpaca-13b | 52K | 4.53 |
| openchat-13b-v1 | 8K | 5.22 |
| baize-v2-13b | 56K | 5.75 |
| vicuna-13b-v1.1 | 70K | 6.31 |
| wizardlm-13b | 70K | 6.35 |
| vicuna-13b-v1.3 | 125K | 6.39 |
| TagLM-13b-v1.0 | 6K | 6.44±0.04 |
- InsTag は正規化後に約 6,587 個の原子タグを生み出し、SFTデータの多様性と複雑さの分析を可能にする。
- タグの多様性と複雑さが高いデータセットほど、MT-Benchの整列性能と相関する。
- TagLM-13b-v1.0 (6K data) は MT-Bench 6.44±0.04 を達成し、データサイズが大きい多くのオープンソース整列LLMを上回る。
- TagLM-13b-v2.0 (6K data) は MT-Bench 6.55±0.02 を達成し、LLaMA-2 chat のパフォーマンスに近づき、RLHF-tuned 相当分に近い。
- InsTag 選択データで訓練したモデルは、SFTデータをはるかに多く使用するオープンリソースのベースラインを上回ることができる。
- InsTag のタグ付け品質は高い精度と一貫性を示す(GPT-4: 96.1% precision, 86.6% consistency; 人間アノテータは多数決で合意)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。