[論文レビュー] InstanSeg: an embedding-based instance segmentation algorithm optimized for accurate, efficient and portable cell segmentation
InstanSeg は埋め込みベースのインスタンスセグメンテーションパイプラインで、細胞/核のセグメンテーションにおいて高い精度と著しく高速な推論を実現し、TorchScript のシリアライズと簡易統合のための QuPath 拡張を備える。
Cell and nucleus segmentation are fundamental tasks for quantitative bioimage analysis. Despite progress in recent years, biologists and other domain experts still require novel algorithms to handle increasingly large and complex real-world datasets. These algorithms must not only achieve state-of-the-art accuracy, but also be optimized for efficiency, portability and user-friendliness. Here, we introduce InstanSeg: a novel embedding-based instance segmentation pipeline designed to identify cells and nuclei in microscopy images. Using six public cell segmentation datasets, we demonstrate that InstanSeg can significantly improve accuracy when compared to the most widely used alternative methods, while reducing the processing time by at least 60%. Furthermore, InstanSeg is designed to be fully serializable as TorchScript and supports GPU acceleration on a range of hardware. We provide an open-source implementation of InstanSeg in Python, in addition to a user-friendly, interactive QuPath extension for inference written in Java. Our code and pre-trained models are available at https://github.com/instanseg/instanseg .
研究の動機と目的
- diverse microscopy datasets.
- 高い精度と効率を大型・実世界のバイオメドデータセットで実現する。
- TorchScript でのシリアライズと横断言語統合(QuPath 拡張)を通じてポータビリティと使いやすさを高める。
- 既存の生物画像ワークフローへ統合可能なEnd-to-end、GPU加速、非独自プロプライエタリなパイプラインを提供する。
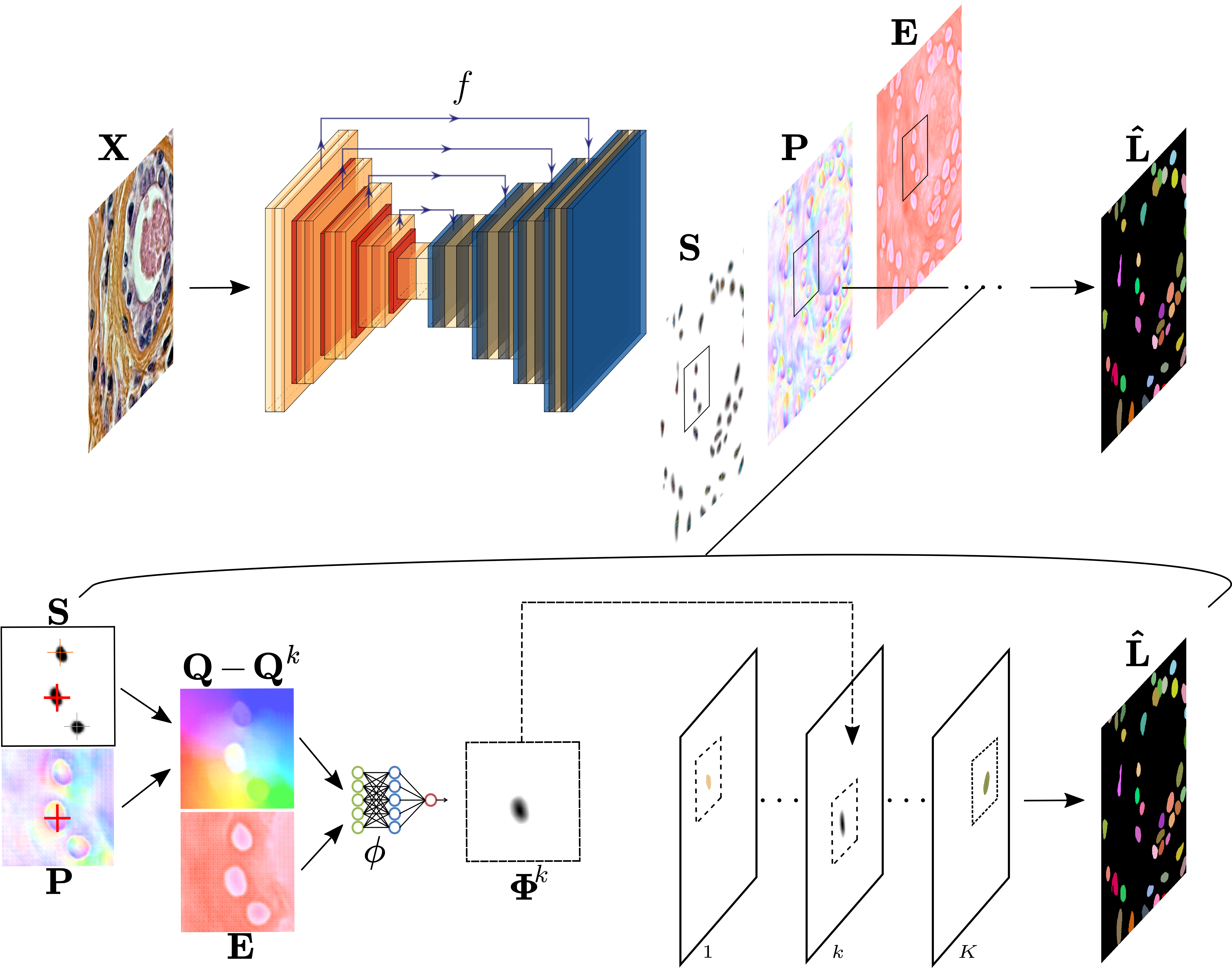
提案手法
- 改良された UNet バックボーンを用いたEmbedベースのセグメンテーション。
- Seedベースのピクセル割り当て:seed map、位置埋め込み、条件付き埋め込みを予測。
- ピクセルオフセットと埋め込みを用いるニューラルネットヘッド Phi によるInstance確率マッピング。
- 損失関数の組み合わせで訓練:seed loss Ls(インスタンス境界までの距離)と instance loss Li(Lovasz hinge with one-vs-rest labeling)。
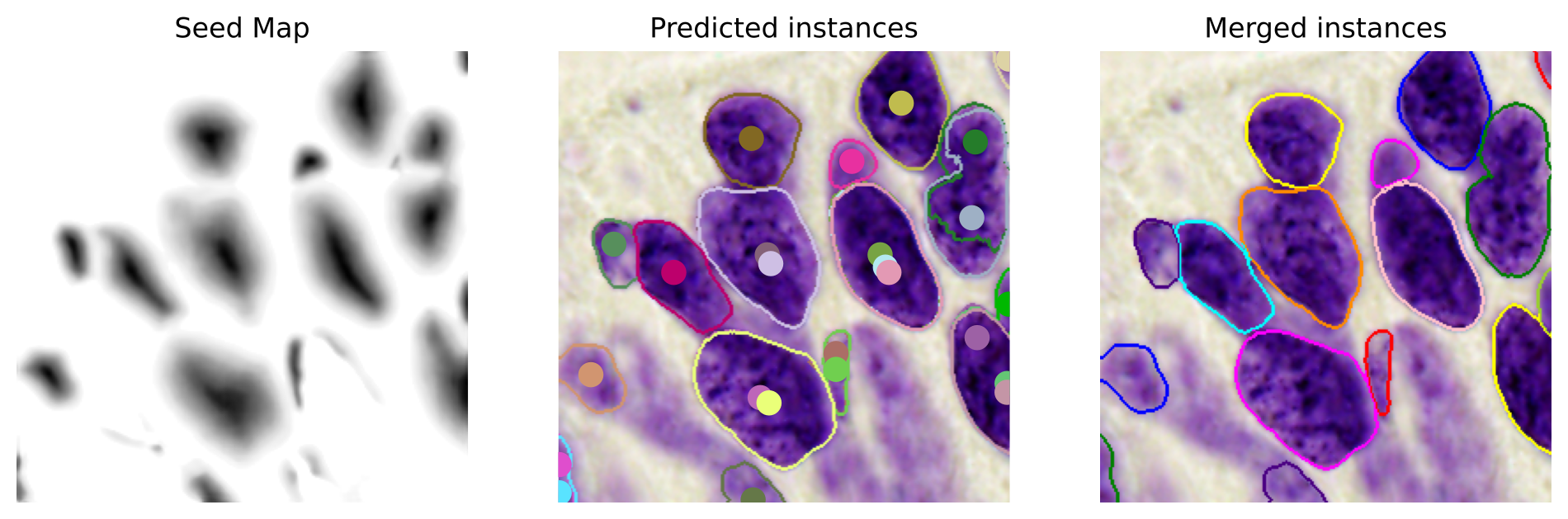
- 推論は局所最大値でシードをサンプリングし、オフセット Qij−Qk を計算し、IoUベースの結合で重複するインスタンス予測を統合。
実験結果
リサーチクエスチョン
- RQ1学習済みシード伝播を伴う埋め込みベースのアプローチは、多様な核データセットで最先端の精度を達成できるのか。
- RQ2シード中心のニューラルクラスタリングアプローチは、接触・重なり核のセグメンテーションを改善しつつ、効率性とポータビリティを維持できるのか。
- RQ3InstanSeg は標準ハードウェア、特にGPU制限環境での推論速度とメモリ使用量においてどう性能を示すのか。
- RQ4方法を非Pythonツールへ(TorchScript)シリアライズし、GUIワークフロー(QuPath 拡張)へ統合しても性能を犠牲にしないのか。
- RQ5より高次元の位置情報/条件付き埋め込みを使用することがセグメンテーション精度に与える影響は何か。
主な発見
| Dataset | StarDist F1_mu | StarDist F1_0.5 | HoVer-Net F1_mu | HoVer-Net F1_0.5 | CellPose F1_mu | CellPose F1_0.5 | EmbedSeg F1_mu | EmbedSeg F1_0.5 | InstanSeg F1_mu | InstanSeg F1_0.5 | InstanSeg F1_mu (TTA) | InstanSeg F1_0.5 (TTA) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TNBC 2018 | 0.645 | 0.896 | 0.546 | 0.768 | 0.627 | 0.835 | 0.641 | 0.870 | 0.699 | 0.898 | 0.704 | 0.899 |
| NuInsSeg | 0.494 | 0.799 | 0.374 | 0.635 | 0.497 | 0.788 | 0.492 | 0.761 | 0.511 | 0.787 | 0.527 | 0.805 |
| MoNuSeg | 0.543 | 0.846 | 0.438 | 0.707 | 0.553 | 0.850 | - | - | 0.575 | 0.861 | 0.566 | 0.860 |
| IHC TMA | 0.470 | 0.798 | 0.304 | 0.559 | 0.545 | 0.811 | - | - | 0.560 | 0.836 | 0.573 | 0.834 |
| CoNSeP | 0.418 | 0.690 | 0.312 | 0.538 | 0.389 | 0.626 | - | - | 0.483 | 0.706 | 0.491 | 0.709 |
| LyNSeC | 0.701 | 0.920 | 0.659 | 0.886 | 0.701 | 0.911 | - | - | 0.724 | 0.923 | 0.725 | 0.922 |
- InstanSegは6つの公開核データセットで最先端または競合的な精度を達成し、ベースラインをしばしば上回る。
- 推論はベースラインより大幅に高速で、ノートパソコンのGPU上で199画像、36,073インスタンスを含む場合の総推論約9.4秒、後処理時間はEmbedSegより著しく低い。
- TorchScriptでシリアライズされたモデルとQuPath拡張により、AppleおよびNVIDIAハードウェアでのGPU加速を含むポータブルで多言語対応の利用が可能。
- 高次元の位置埋め込み(De > 2)を追加し、条件付き埋め込み(De > 0)を含める Ablation で精度向上を示す;これらの要素を除去すると性能が劣化。
- データセットを横断して、InstanSeg は一貫して StarDist、HoVer-Net、CellPose、EmbedSeg を F1 指標で上回り、TTA はほとんどのケースでさらなる利得を提供。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。