[論文レビュー] Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
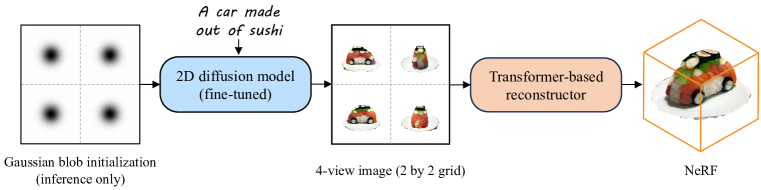
Instant3D は2段階のフィードフォワードパイプラインを用いる: (1) テキストから2x2のスパースビュー画像グリッドを生成するために2D拡散モデルを微調整し、(2) トランスフォーマーベースのスパースビュー再構成器を用いて NeRF を回帰させ、約20秒で高品質な3D資産を提供する。
Text-to-3D with diffusion models has achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate low-quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner. We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate diverse 3D assets of high visual quality within 20 seconds, which is two orders of magnitude faster than previous optimization-based methods that can take 1 to 10 hours. Our project webpage: https://jiahao.ai/instant3d/.
研究の動機と目的
- 高速で多様な生成を可能にすることで、遅い最適化ベースのテキスト-to-3D 手法を克服する。
- 事前学習済みの2D拡散事前知識を活用して、スパースビューでの3D再構築をガイドする。
- スパースビュー2D生成に続く、大型TransformerベースのNeRF再構成を組み込んだ2段階パイプラインを開発する。
- 高速推論を維持しつつ、高い視覚的品質と視点的一貫性を達成する。
提案手法
- 事前学習済みの2D テキスト画像拡散モデル(SDXL)を微調整し、1回のデノイズパスで4視点の2x2グリッドを生成する。
- 推論をガウス blob で初期化して白背景出力を促進し、第二段階の再構築を改善する。
- Objaverse(約75万個のオブジェクト)からデータセットを作成し、軽量なファインチューニング(10Kステップ、10K curated samples)で一貫したマルチビュー画像を生成する。
- 4つの姿勢情報付き画像トークンからトリプレーン NeRF を回帰する、トランスフォーマー系のスパースビュー大規模再構成モデルを導入する。
- カメラモジュレーションを備えたViTベースの画像エンコーダを用いて姿勢認識トークンを生成し、次にクロスアテンションと自己注意を用いた画像-to-triplaneデコーダと、密度と色を出力するNeRF MLP、体積レンダリングを適用する。
- Objaverseレンダリング(512x512)でランダムビューを用いて頑健性を高めて訓練する。推論は第一段階の固定カメラ姿勢を使用する。

実験結果
リサーチクエスチョン
- RQ1テキストプロンプトを、要求された概念を捉えた一貫したスパース4ビュー画像グリッドに変換できるか?
- RQ2大規模トランスフォーマーベースモデルが、シーンごとの最適化なしに4つのスパースビューからNeRFを再構成できるか?
- RQ32段階のフィードフォワードアプローチは、最適化ベースの手法に対して競争力のあるまたは優れた品質と多様性を達成しつつ、大幅な速度向上を実現するか?
主な発見
| Method | ViT-L/14 ↑ | ViT-bigG-14 ↑ | Time(s) ↓ |
|---|---|---|---|
| Shap-E | 20.51 | 32.21 | 6 |
| DreamFusion | 23.60 | 37.46 | 5400 |
| ProlificDreamer | 27.39 | 42.98 | 36000 |
| Ours | 26.87 | 41.77 | 20 |
- 約20秒で3D資産を生成し、従来の最適化ベース手法より約200倍速い。
- CLIPベースのテキスト-3D整合性でShap-EとDreamFusionを上回り、ProlificDreamerと整合性と品質で競合。
- 微調整したSDXLモデルで生成すると、2x2のスパースビュー画像グリッドは良好な視点一貫性を示す。
- トランスフォーマー型のスパースビュー再構成器は、GSOデータセットでSparseNeusより高いPSNR(26.54)とSSIM(0.8934)、低いLPIPS(0.0643)を達成。
- Instant3D の推論は大幅な速度向上を示し(20s vs DreamFusionの1.5h、ProlificDreamerの10h)。
- CLIPベースの評価は強いテキスト-3D整合を示し、手法はCLIPスコア(ViT-L/14: 26.87; ViT-bigG-14: 41.77)を達成してShap-Eを上回り、ProlificDreamerに近づく。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。