[論文レビュー] Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model
Instruct2Act は SAM/CLIP を介して知覚を調整し、プランニングと実行を統括する Python ポリシーを生成する LLM を用いて、ファインチューニングなしでゼロショットの多モーダル指示 grounding を可能にする。
Foundation models have made significant strides in various applications, including text-to-image generation, panoptic segmentation, and natural language processing. This paper presents Instruct2Act, a framework that utilizes Large Language Models to map multi-modal instructions to sequential actions for robotic manipulation tasks. Specifically, Instruct2Act employs the LLM model to generate Python programs that constitute a comprehensive perception, planning, and action loop for robotic tasks. In the perception section, pre-defined APIs are used to access multiple foundation models where the Segment Anything Model (SAM) accurately locates candidate objects, and CLIP classifies them. In this way, the framework leverages the expertise of foundation models and robotic abilities to convert complex high-level instructions into precise policy codes. Our approach is adjustable and flexible in accommodating various instruction modalities and input types and catering to specific task demands. We validated the practicality and efficiency of our approach by assessing it on robotic tasks in different scenarios within tabletop manipulation domains. Furthermore, our zero-shot method outperformed many state-of-the-art learning-based policies in several tasks. The code for our proposed approach is available at https://github.com/OpenGVLab/Instruct2Act, serving as a robust benchmark for high-level robotic instruction tasks with assorted modality inputs.
研究の動機と目的
- 大規模言語モデルを活用して多モーダル指示を実行可能なロボット操作シーケンスへ翻訳する。
- 知覚 API(SAM と CLIP)を LLM 生成コントロールコードと統合し、知覚–計画–行動ループを作成する。
- 多様な卓上操作タスクでゼロショット性能を評価し、モダリティとシナリオ間の一般化を検証する。
提案手法
- API 定義、ライブラリインポート、および文脈内サンプルを含む構造化プロンプトを LLM に提供し、main() Python 関数を生成する。
- SAM を用いてセグメンテーションマスクを生成し、CLIP を用いてオブジェクトのクロップを分類して意味的グラウンドを行う。
- 事前定義された変換と境界クランピングを介して、画像空間情報をロボットの動作空間へ翻訳する。
- 純粋な言語、言語+視覚、指差し言語の指示を処理する柔軟なモダリティマネージャを組み込む。
- 知覚の信頼性を高めるため、画像前処理、マスク後処理、NMS などの処理モジュールを適用する。
- ゼロショット性能を SOTA ベースラインと比較するために VIMA Bench のメタタスクで評価する。
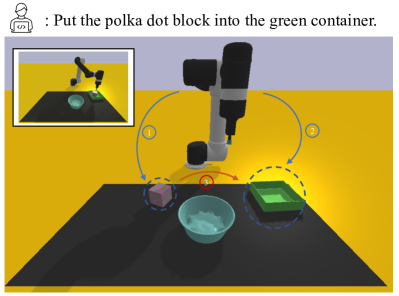
実験結果
リサーチクエスチョン
- RQ1マルチモーダル入力をロボットアクションへ mapping する実行可能でモジュラーなポリシーコードを、タスク固有の訓練なしで LLM が生成できるか。
- RQ2知覚基盤モデル(SAM/CLIP)は LLM の推論とどのように統合され、指示を現実のロボットアクションへ grounded するのか。
- RQ3処理ステップとバックボーンの選択が、タスクとモダリティを跨ぐゼロショット操作成功にどう影響するか。
- RQ4VIMA Bench の L1/L2/L3 ジェネラリゼーション設定で Instruct2Act はどの程度 generalize するか。
- RQ5完全なゼロショット、ファウンデーションモデル主導のロボットシステムの制約とロバスト性の特性は何か。
主な発見
| モデル | タスク01 | タスク02 | タスク03 | タスク04 | タスク05 | タスク17 | 平均 |
|---|---|---|---|---|---|---|---|
| DT-20M | 60.5 | 64.0 | 50.5 | 44.0 | 41.0 | 2.5 | 43.8 |
| Gato-20M | 61.5 | 62.0 | 32.5 | 49.0 | 38.0 | 2.0 | 40.8 |
| Flamingo-20M | 63 | 61.5 | 55.0 | 50.0 | 42.5 | 1.0 | 45.5 |
| VIMA-20M | 100 | 100 | 100 | 99.5 | 59.5 | 47.5 | 84.4 |
| Ours-Multi | 91.3 | 81.4 | 98.2 | 78.5 | 72.0 | 85.2 | 84.4 |
| Ours-Single | 86.7 | - | 94.6 | - | - | 63.0 | - |
- Instruct2Act は six つの VIMA Bench メタタスクにおいてゼロショット設定で SOTA VIMA に対して競争力のある平均性能を達成。
- マルチモーダル指示は、より豊かな文脈的グラウンドのために一般に単一モーダル指示より優れている。
- マスク後処理と画像前処理のアブレーションにより、平均成功率が 84.1% に向上。
- より大きな SAM/CLIP バックボーンは実験全体で SR% を改善。
- 人間の介入、誤入力、同義語などの指示に対してもアプローチは頑健である。
- 異なる LLM(ChatGPT、LLaMA-Adapter)は妥当な結果を生み出す可能性があり、生成リトライとともに性能が向上する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。