[論文レビュー] Intel nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning
この論文は、深層学習の性能をフレームワーク間およびハードウェアバックエンド間で最適化するためのフレームワーク-ブリッジ型中間表現とコンパイラ-実行環境スタックである Intel nGraph を提示します。
The Deep Learning (DL) community sees many novel topologies published each year. Achieving high performance on each new topology remains challenging, as each requires some level of manual effort. This issue is compounded by the proliferation of frameworks and hardware platforms. The current approach, which we call "direct optimization", requires deep changes within each framework to improve the training performance for each hardware backend (CPUs, GPUs, FPGAs, ASICs) and requires $\mathcal{O}(fp)$ effort; where $f$ is the number of frameworks and $p$ is the number of platforms. While optimized kernels for deep-learning primitives are provided via libraries like Intel Math Kernel Library for Deep Neural Networks (MKL-DNN), there are several compiler-inspired ways in which performance can be further optimized. Building on our experience creating neon (a fast deep learning library on GPUs), we developed Intel nGraph, a soon to be open-sourced C++ library to simplify the realization of optimized deep learning performance across frameworks and hardware platforms. Initially-supported frameworks include TensorFlow, MXNet, and Intel neon framework. Initial backends are Intel Architecture CPUs (CPU), the Intel(R) Nervana Neural Network Processor(R) (NNP), and NVIDIA GPUs. Currently supported compiler optimizations include efficient memory management and data layout abstraction. In this paper, we describe our overall architecture and its core components. In the future, we envision extending nGraph API support to a wider range of frameworks, hardware (including FPGAs and ASICs), and compiler optimizations (training versus inference optimizations, multi-node and multi-device scaling via efficient sub-graph partitioning, and HW-specific compounding of operations).
研究の動機と目的
- 深層学習ワークロードを加速させるためのフレームワーク依存・バックエンド依存性のない経路の必要性を動機づける。
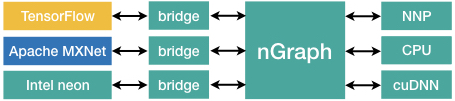
- nGraph 中間表現とそのグラフベースの構造を説明する。
- frontend グラフを nGraph IR に翻訳するフレームワークブリッジを説明する。
- transformer バックエンドと、それらが CPU、NNP、GPU のために最適化済みコードを生成する方法を概説する。
- 将来のフレームワーク、ハードウェア、最適化のカバレッジ拡張の方向性を論じる。
提案手法
- フレームワーク非依存 IR を、入力、出力、属性を持つ stateless な操作ノードの有向非巡回グラフとして定義する。
- TensorFlow、MXNet、neon などの frontend 計算グラフを nGraph IR に変換するフレームワークブリッジを説明する。
- 特定バックエンド向けに IR をコンパイルし、メモリ管理、レイアウト処理、カーネル選択を提供するトランスフォーマを説明する。
- CPU(MKL-DNN)、NNP、NVIDIA GPU(cuDNN、LLVM/PTX)向けのバックエンド固有のトランスフォーマを詳述する。
- グラフ内の集団通信および点-to-点通信をトランスフォーマを通じてサポートする(MPI または最適化された方法)。
- ONNX との相互運用性と、今後の作業でのより広範なフレームワークおよびハードウェアサポートの計画を提案する。
実験結果
リサーチクエスチョン
- RQ1フレームワークに依存しない IR が複数のバックエンドに渡る最適化済み深層学習実行をどのように可能にするか。
- RQ2frontend グラフを nGraph IR に翻訳する際のフレームワークブリッジの役割は何か。
- RQ3CPU、NNP、GPU バックエンドのコード生成をトランスフォーマがどのように最適化するか。
- RQ4学習および多ノード/多デバイススケーリングをサポートするための潜在的な拡張とは何か。
- RQ5 evolving standards や他のコンパイラ/IR の深層学習取り組みと nGraph がどう相互運用できるか。
主な発見
- nGraph はフレームワークを橋渡しする IR を提供し、バックエンドが CPUs、NNPs、GPUs 上で同じ計算を実行できるようにする。
- Transformers はバックエンド最適化コードを生成し、MKL-DNN や cuDNN のようなライブラリと統合してハードウェア機能を活用する。
- IR は stateless operation nodes の有向非巡回グラフで、最適化のために適応可能なデータレイアウトと属性を持つ。
- nGraph は frontend グラフを IR にマッピングするフレームワークブリッジを介したエンドツーエンドのコンパイルおよび実行ワークフローをサポートする。
- より広い相互運用性(例:ONNX)と今後の作業での追加フレームワークおよびハードウェアへの拡張の展望がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。