[論文レビュー] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
tldr: InternImage を導入します。Deformable convolutions (DCNv3) を用いた大規模な CNN ベースのビジョン基盤モデルで、分類・検出・セグメンテーションにおいて、1B パラメータ級までのスケール変異でも大規模な ViTs にマッチするか、あるいはそれを上回ることを目指します。大量データを用いて ImageNet で ViTs との差を縮めつつ、COCO の検出で最先端を達成し、ADE20K セグメンテーションも堅実にします。
Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs. The code will be released at https://github.com/OpenGVLab/InternImage.
研究の動機と目的
- ViT と同様にパラメータとデータ量でスケールさせる CNN ベースの基盤モデルの動機づけ。
- 長距離依存と適応的な空間集約を可能にする変形畳み込み核演算子を設計。
- 大規模学習に適したブロック設計と積み重ね戦略を備えたスケーラブルな CNN バックボーン(InternImage)を開発。
- 分類・検出・セグメンテーションにおいて、最新の CNN および ViTs と対等かそれ以上の性能を示す。
提案手法
- 効率性を重視して、核心演算子として 3x3 の疎行列性を持つ変形畳み込み v3 (DCNv3) を採用。
- DCNv2 を拡張: (i) サンプリング点間で投影重みを共有; (ii) 多様な集約パターンのためのマルチグループ機構を導入; (iii) 学習安定性のためソフトマックスで変調スカラーを正規化。
- DCNv3 を用いた LN と FFN を組み込んだ基本ブロックと、オフセットとスケールを予測する分離経路を構築。
- ステムとダウンサンプリングのレイアウトを用いて階層的な特徴ピラミッドを作成。
- 4 段階ネットワークを形成するスタッキング規則を定義し、4つの主要ハイパーパラメータ (C1, C′, L1, L3) を用いてファミリー (T/S/B/L/XL/H) を導出。
- 先行研究に触発された深さ/幅のスケーリング規則を提示し、マルチスケール変種を生成、1B パラメータの InternImage-H を含む。
![Figure 1 : Comparisons of different core operators. (a) shows the global aggregation of multi-head self-attention (MHSA) [ 1 ] , whose computational and memory costs are expensive in downstream tasks that require high-resolution inputs. (b) limits the range of MHSA into a local window [ 2 ] to reduc](https://ar5iv.labs.arxiv.org/html/2211.05778/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1変形畳み込みを用いた CNN 基盤モデルは、非常に大規模なスケールとデータレジームにおいて ViT ベースのモデルと同等またはそれを上回ることができるか?
- RQ2DCNv3 をどのように調整・スタックして、視覚タスクにおける長距離依存と適応的な空間集約を効率的に学習させるか?
- RQ3複数のスケールで、ImageNet、COCO、ADE20K における InternImage の性能向上は、同時代の CNN および ViT と比較してどの程度か?
主な発見
| モデル | パラメータ数 | FLOPs | Top-1 精度(ImageNet) |
|---|---|---|---|
| InternImage-T (origin) | 30M | 5G | 83.5% |
| InternImage-S | 50M | 8G | 84.2% |
| InternImage-B | 97M | 16G | 84.9% |
| InternImage-L | 223M | 108G | 87.7% |
| InternImage-XL | 335M | 163G | 88.0% |
| InternImage-H | 1.08B | 188G | 88.9% |
- InternImage-T は ImageNet-1K のトップ-1 精度 83.5% を達成し、ConvNeXt-T を 1.4 ポイント上回る。
- InternImage-S は ImageNet-1K で 84.2% のトップ-1、InternImage-B は 84.9% のトップ-1 に達し、いずれも同等スケールの従来の CNN と競合または上回る。
- 大規模データで、InternImage-H は ImageNet-1K で 89.6% のトップ-1 精度を達成し、最先端の ViT やハイブリッド ViT に近づく。
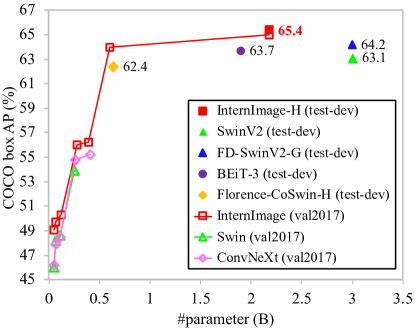
- COCO では InternImage-H が test-dev で新記録の 65.4 ボックス AP を 2.18B パラメータで達成し、SwinV2-G を上回り、多くのケースでパラメータ数が少なく高効率を実現。
- ADE20K では InternImage-H が 60.3 MS mIoU(マルチスケール)を達成し、InternImage-B/L/XL が従来の CNN を上回り、強力なセグメンテーション性能を示す。
- InternImage は、ImageNet 分類、COCO 検出、ADE20K セグメンテーションのタスク全体で、数千万から十億を超えるパラメータへとスケールさせつつ、ViT レベルに迫る性能向上を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。