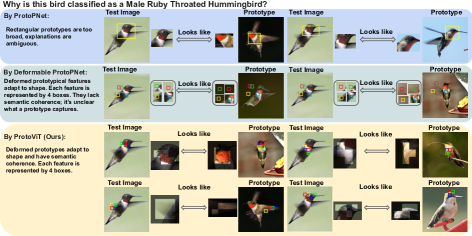
[論文レビュー] Interpretable Image Classification with Adaptive Prototype-based Vision Transformers
ProtoViT は Vision Transformer のバックボーンを適応的な変形可能プロトタイプと組み合わせ、ケースベースの推論による解釈可能な画像分類を可能にし、プロトタイプベースのモデルの中で最新の精度を達成しつつ、一貫性があり忠実な説明を保証します。
We present ProtoViT, a method for interpretable image classification combining deep learning and case-based reasoning. This method classifies an image by comparing it to a set of learned prototypes, providing explanations of the form ``this looks like that.'' In our model, a prototype consists of \textit{parts}, which can deform over irregular geometries to create a better comparison between images. Unlike existing models that rely on Convolutional Neural Network (CNN) backbones and spatially rigid prototypes, our model integrates Vision Transformer (ViT) backbones into prototype based models, while offering spatially deformed prototypes that not only accommodate geometric variations of objects but also provide coherent and clear prototypical feature representations with an adaptive number of prototypical parts. Our experiments show that our model can generally achieve higher performance than the existing prototype based models. Our comprehensive analyses ensure that the prototypes are consistent and the interpretations are faithful.
研究の動機と目的
- 高リスク領域で解釈可能な画像分類器の必要性を動機づける。
- Vision Transformer バックボーンを用いるプロトタイプベースのフレームワークを開発する。
- 適応的で幾何学的に柔軟なプロトタイプと一貫性のある忠実な説明を実現する。
- 解釈性を保持しつつ精度を最大化するトレーニング手順を提示する。
提案手法
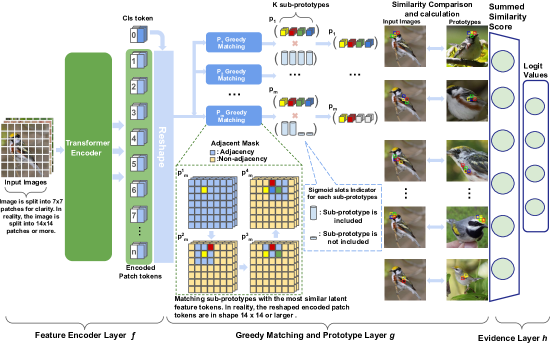
- 画像パッチから latent tokens を生成する特徴抽出器 f として ViT バックボーンを使用する。
- サブプロトタイプの集合としてプロトタイプを定義し、greedy matching layer g を適用してサブプロトタイプと潜在トークンをペアさせる。
- サブプロトタイプ間の幾何的連続性を保証する隣接マスクを組み込む。
- 適応スロット機構を導入してプロトタイプごとに動的なサブプロトタイプ数を許容する。
- 視覚的説明のためにプロトタイプを最も近い潜在パッチに射影し、最終分類のためのエビデンス層 h を最適化する。
- クラスタリング、分離、整合性、および直交性項を含む段階的損失で訓練し、続いてプロトタイプの剪定と射影を行う。
実験結果
リサーチクエスチョン
- RQ1ProtoViT は既存のプロトタイプベースのモデルより高い精度を達成しつつ解釈性を維持できるか?
- RQ2適応的で変形可能なプロトタイプは多様なデータセットに対して一貫した忠実なプロトタイプ説明を提供するか?
- RQ3視覚的推論における幾何学的変動と位置ずれを ProtoViT はどのように処理するか?
- RQ4プロトタイプ射影がモデルの性能と解釈性に与える影響は?
主な発見
| Architecture | Model | CUB Acc(%) | Car Acc(%) |
|---|---|---|---|
| ProtoPNet | (9) | 80.1 ± 0.3 | 89.5 ± 0.2 |
| Densenet-161 | Def. ProtoPNet(2x2) (given in [ 10 ] ) | 80.9 ± 0.22 | 88.7 ± 0.3 |
| ProtoPool | (13) | 80.3 ± 0.3 | 90.0 ± 0.3 |
| TesNet | (14) | 81.5 ± 0.3 | 92.6 ± 0.3 |
| Base | (given in [ 23 ] ) | 80.57 | 86.21 |
| DeiT-Tiny | ViT-Net (given in [ 23 ] ) | 81.98 | 88.41 |
| ProtoPFormer | (given in [ 23 ] ) | 82.26 | 88.48 |
| ProtoViT(K=4,r=1) | ours | 82.92 ± 0.5 | 89.02 ± 0.1 |
| Baseline | (given in [ 23 ] ) | 84.28 | 90.06 |
| DeiT-Small | ViT-Net (given in [ 23 ] ) | 84.26 | 91.34 |
| ProtoPFormer | (given in [ 23 ] ) | 84.85 | 90.86 |
| ProtoViT(K=4,r=1) | ours | 85.37 ± 0.13 | 91.84 ± 0.3 |
| Baseline | (given in [ 23 ] ) | 83.95 | 90.19 |
| CaiT-XXS 24 | ViT-Net (given in [ 23 ] ) | 84.51 | 91.54 |
| ProtoPFormer | (given in [ 23 ] ) | 84.79 | 91.04 |
| ProtoViT(K=4,r=1) | ours | 85.82 ± 0.15 | 92.40 ± 0.1 |
- ViT バックボーンを用いた ProtoViT は鳥類および車両データセットでいくつかのプロトタイプベース手法より高い精度を達成している。
- K=4 のサブプロトタイプと r=1 の隣接を用いた ProtoViT は 82.92% CUB 精度と 89.02% Car 精度を達成(DeiT バックボーン)。
- CaiT-XXS バックボーンを用いた ProtoViT は 85.82% CUB 精度と 92.40% Car 精度。
- ProtoViT は同じバックボーンを用いた他のプロトタイプベースモデルより優れた精度を示し、実際の画像パッチにマッピングされた視覚的に一貫したプロトタイプを提供する。
- グローバル/ローカル分析は、プロトタイプが意味のある意味的特徴に一貫して対応していることを示す。
- 位置ずれのベンチマークは ProtoViT が PLC、PAC、PRC の点で CNN ベースのプロトタイプモデルと同等か、それ以上の性能を示しつつ、精度も競争力がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。