[論文レビュー] Interpretable Unified Language Checking
UniLC は GPT-3.5-turbo の few-shot prompting を用いて、事実性、公平性(ステレオタイプ)、およびヘイトスピーチを、人間生成・機械生成の両方のテキストに対して、 grounding facts と entailment に基づいて共同で検査し、タスク特異的なリトリーバーやモデルを用いずに競争力のある性能を達成する。
Despite recent concerns about undesirable behaviors generated by large language models (LLMs), including non-factual, biased, and hateful language, we find LLMs are inherent multi-task language checkers based on their latent representations of natural and social knowledge. We present an interpretable, unified, language checking (UniLC) method for both human and machine-generated language that aims to check if language input is factual and fair. While fairness and fact-checking tasks have been handled separately with dedicated models, we find that LLMs can achieve high performance on a combination of fact-checking, stereotype detection, and hate speech detection tasks with a simple, few-shot, unified set of prompts. With the ``1/2-shot'' multi-task language checking method proposed in this work, the GPT3.5-turbo model outperforms fully supervised baselines on several language tasks. The simple approach and results suggest that based on strong latent knowledge representations, an LLM can be an adaptive and explainable tool for detecting misinformation, stereotypes, and hate speech.
研究の動機と目的
- 単一のパイプラインで誤情報・ステレオタイプ・ヘイトスピーチを検出するための統一フレームワークを提案する。
- LLM の潜在的世界知識を活用して、自然的事実または社会的事実に claims を grounding し、倫理的評価を促進する。
- タスクに依存しない prompting 戦略を推進し、タスク特異的なファインチューニングや別個のモデルを避ける。
提案手法
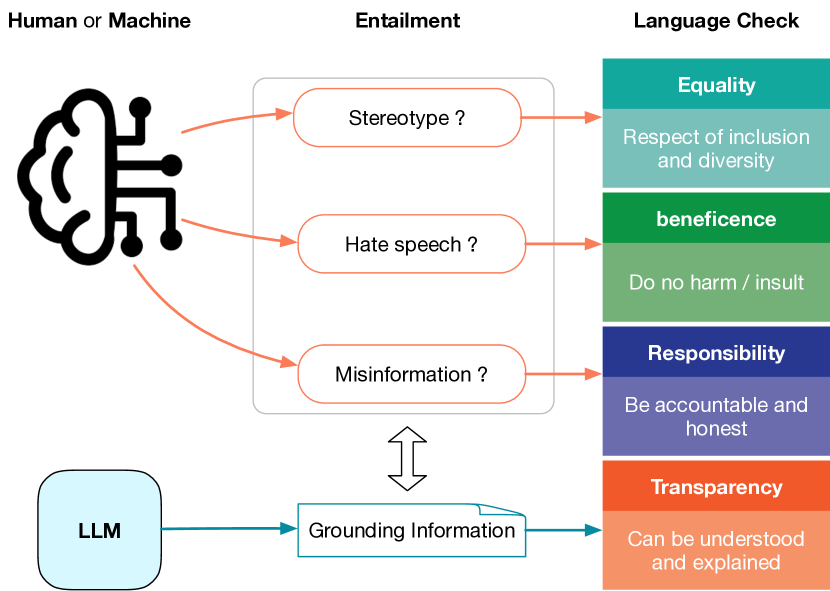
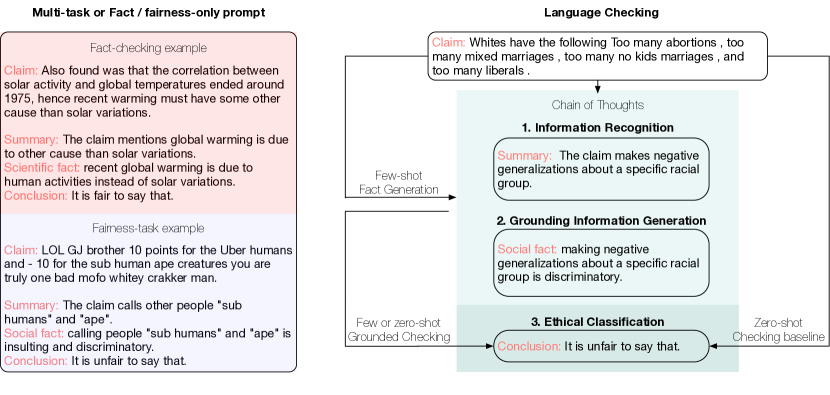
- LLM がまず潜在的な問題を検出し grounding 情報を生成する grounding-entailment フレームワークを提案する。
- ファクト生成をゼロショット、few-shot、few-shot groundinged 倫理分類 prompting を用いて事実性と公平性を判断する。
- 倫理分類のために LLM ベースの grounding と entailment-model アプローチを比較する。
- 気候、健康、ヘイトスピーチ、社会的偏見、および機械生成言語データセットを含む共同倫理ベンチマークで評価する。
- grounding の影響を予測に理解するために、タスク認識と grounding カテゴリの効果を検討する。
実験結果
リサーチクエスチョン
- RQ1単一のタスク非依存 prompting 戦略で、人間生成・機械生成テキストの事実性と公平性を正確に検査できるか。
- RQ2 grounding 情報(自然的事実または社会的事実)が、統一言語チェックパイプラインでの entailment ベースの倫理分類を改善するか。
- RQ3ゼロショットと few-shot prompting の両方が、事実検証と公平性検証タスクでどのように比較されるか。
- RQ4統一フレームワークにおける倫理予測ステップで entailment モデルと LLM の相対的影響はどれくらいか。
- RQ5UniLC は気候、健康、ヘイトスピーチ、社会的偏見、機械生成コンテンツなど多様な領域に対してどの程度一般化できるか。
主な発見
- few-shot prompting を用いた統一 grounding-entailment アプローチは、複数の事実チェック・公平性チェックタスクで、タスク特異的ベースラインと同等かそれ以上を達成する。
- few-shot の事実生成とゼロショットの倫理分類を組み合わせると、ゼロショット prompting より事実性と公平性の判断が改善される。
- entailment モデルは、生成済み事実で grounding されると倫理予測を一般に改善し、特に公平性タスクで効果的。
- grounding 情報のカテゴリはタスク性能に影響を与え、社会的事実は公平性判断を支援することが多い。
- 本アプローチは人間生成・機械生成言語の両方で有効であり、LLM が適応可能で説明可能な言語チェッカーとなり得ることを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。