[論文レビュー] Introducing Bode: A Fine-Tuned Large Language Model for Portuguese Prompt-Based Task
この論文は、プロンプトベースのタスクのために微調整されたLLaMA 2ベースのポルトガル語LLM(7Bと13B)であるBodeを提示し、ゼロショットおよびインコンテキスト学習を用いて感情分析、ニュース分類、偽ニュース検出を評価します。
Large Language Models (LLMs) are increasingly bringing advances to Natural Language Processing. However, low-resource languages, those lacking extensive prominence in datasets for various NLP tasks, or where existing datasets are not as substantial, such as Portuguese, already obtain several benefits from LLMs, but not to the same extent. LLMs trained on multilingual datasets normally struggle to respond to prompts in Portuguese satisfactorily, presenting, for example, code switching in their responses. This work proposes a fine-tuned LLaMA 2-based model for Portuguese prompts named Bode in two versions: 7B and 13B. We evaluate the performance of this model in classification tasks using the zero-shot approach with in-context learning, and compare it with other LLMs. Our main contribution is to bring an LLM with satisfactory results in the Portuguese language, as well as to provide a model that is free for research or commercial purposes.
研究の動機と目的
- 高品質なポルトガル語NLPモデルのギャップを埋め、ポルトガル語の指示追随タスクに特化した公開可能なLLMを開発する。
- LLaMA 2アーキテクチャをポルトガル語データセットで微調整してポルトガル語に適応させる。
- ゼロショットおよびインコンテキスト学習設定でポルトガル語分類タスクにおけるBodeを評価する。
- Bodeを他のオープンLMLと比較して、ポルトガル語プロンプトにおける相対的な強みを評価する。
提案手法
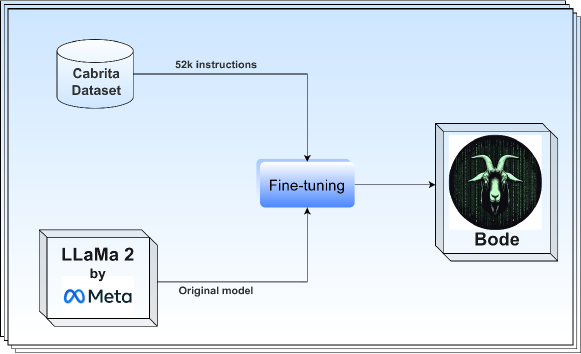
- ポルトガル語の指示追随データセットに由来するデータを用いてLLaMA 2を微調整する。
- 微調整時にalpha=32およびdropout=0.05のLow-Rank Adaptation (LoRA)を適用する。
- 追加のタスク固有トレーニングを行わず、評価にはゼロショットおよびインコンテキスト学習を採用する。
- 感情分析およびニュース分類タスクの回答を導くためにプロンプトエンジニアリングを使用する。
- 3つのポルトガル語データセット(TweetSentBr multiclass、TweetSentBr binary、AGNews multiclass、FakeRecogna binary)で評価する。
- Cabrita/openCabrita、Falcon-7B、LLaMA-2 7B/13B、Mistral-7Bのベースラインモデルと比較する。
実験結果
リサーチクエスチョン
- RQ1LLaMA 2に基づくポルトガル語特化の微調整LLMは、ゼロショットおよびインコンテキスト学習の下で感情分析、ニュース分類、偽ニュース検出において競争力のある精度を達成できるか。
- RQ213BパラメータのBodeは、7Bの同等モデルおよび他のオープンポルトガル語LLMをこれらのタスクで上回るか。
- RQ3プロンプトエンジニアリングとLoRAベースの微調整は、ポルトガル語指示追随性能にどのような影響を与えるか。
主な発見
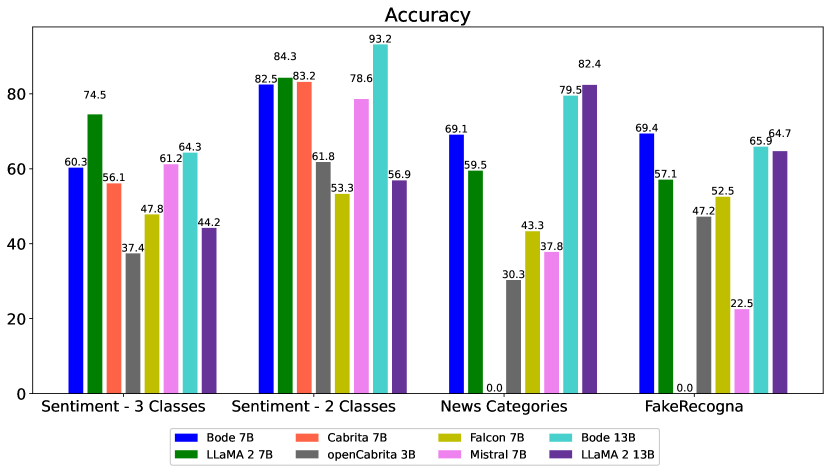
- Bode 13Bは感情分析タスクで90%以上の精度を達成し、ベースのLLaMA 2 13Bが56.9%に達したのを上回った。
- 多クラスのニュース分類では、Bode 7Bが7Bモデルの中で最高の性能を示し、13Bモデルの中ではLLaMA 2 13Bが小さな差で優位だった。
- 偽ニュース検出では、両方のBodeモデルがベースモデルを上回り、タスクを横断して安定した性能を示した。
- 全体として、Bode 7Bおよび13Bは、タスク依存のばらつきはあるものの、一般にベースのオープンポルトガル語LLMと同等以上の性能を示した。
- 著者は、LLaMA 2 7B/13Bと比較してBodeの性能が落ち込む可能性のある原因として、破滅的忘却(catastrophic forgetting)を挙げている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。