[論文レビュー] Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation
本論文は、ChatGPT(gpt-3.5-turbo)を複数言語および文書レベルのタスクにおける文法エラー訂正(GEC)に適用し、ゼロショットおよびfew-shotの連鎖思考 prompting を用いて評価し、SOTAモデルおよび Grammarly と比較しています。
ChatGPT, a large-scale language model based on the advanced GPT-3.5 architecture, has shown remarkable potential in various Natural Language Processing (NLP) tasks. However, there is currently a dearth of comprehensive study exploring its potential in the area of Grammatical Error Correction (GEC). To showcase its capabilities in GEC, we design zero-shot chain-of-thought (CoT) and few-shot CoT settings using in-context learning for ChatGPT. Our evaluation involves assessing ChatGPT's performance on five official test sets in three different languages, along with three document-level GEC test sets in English. Our experimental results and human evaluations demonstrate that ChatGPT has excellent error detection capabilities and can freely correct errors to make the corrected sentences very fluent, possibly due to its over-correction tendencies and not adhering to the principle of minimal edits. Additionally, its performance in non-English and low-resource settings highlights its potential in multilingual GEC tasks. However, further analysis of various types of errors at the document-level has shown that ChatGPT cannot effectively correct agreement, coreference, tense errors across sentences, and cross-sentence boundary errors.
研究の動機と目的
- ChatGPT の英文・ドイツ語・中国語における文レベルの GEC 能力を、複数の公式テストセットを用いて評価する。
- ゼロショットおよび few-shot における連鎖思考プロンプティングを用いた GEC のインコンテスト学習を調査する。
- 英語の文書レベル GEC における ChatGPT の性能を評価し、エラータイプを分析する。
- 流暢さと編集動作を理解するための自動および手動の人間評価を実施する。
- 非英語および低リソース言語における GEC の性能を検討し、長所と限界を特定する。
提案手法
- ChatGPT を用いた文法エラーを識別・修正しつつ文の構造を保つよう、ゼロショットおよびゼロショットCoTプロンプトを設計する。
- 複数データセットにわたるランダムに選択された文脈例を用いた few-shot CoT プロンプトを開発する。
- 英語・ドイツ語・中国語の5つの文レベルテストセットと、英語の文書レベルセット3つを対象に、自動指標と人間評価を用いて ChatGPT を評価する。
- 適切な場合には M2 Scorer、ERRANT、GLUEベース指標を用いて、Transformer-base、GECToR、T5-large、Grammarly と比較する。
- ERRANT を用いた文書レベル GEC の手動エラータイプ分析を行い、文を跨ぐエラーパターンと限界を特定する。

実験結果
リサーチクエスチョン
- RQ1ゼロショットおよび few-shot CoT プロンプトを用いた場合、英語・ドイツ語・中国語の文レベル GEC において ChatGPT はどの程度の性能を示すか?
- RQ2連鎖思考 prompting は標準プロンプトに比べて ChatGPT の GEC 性能を改善するか?
- RQ3標準ベンチマークおよび流暢さ重視の指標で、ChatGPT は SOTA の GEC 系統および Grammarly とどのように比較されるか?
- RQ4文書レベル GEC における ChatGPT の強みと限界は何か、どのエラータイプに苦戦するか?
- RQ5非英語および低リソース GEC 環境で ChatGPT は効果的か?
主な発見
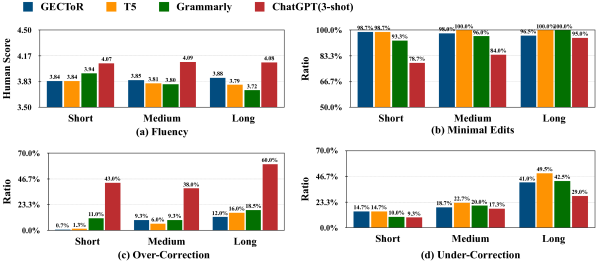
- ChatGPT は、文レベルのタスクで SOTA モデルと比較して再現性が高く流暢さは強力だが、精度と F0.5 は低い。
- Few-shot CoT プロンプトはゼロショットCoT より一般に ChatGPT の性能を向上させ、3-shot が多くの場合最良の成績を示す。一方で5 shots を超えると性能が低下することがある。
- JFLEG の流暢さ重視指標では、ChatGPT の3-shot CoT が SOTA にほぼ匹敵し、T5 large を上回ることもあり、流暢な訂正力が強いことを示す。
- 非英語・低リソース言語では、ChatGPT はスクラッチから学習した Transformer ベースのベースラインよりリコールで優れる場合があるが、精度とF0.5 は劣ることが多く、言語ごとに性能が異なる。
- 文書レベル GEC では、ChatGPT は高いリコールと流暢性を示す一方、跨文のエラー訂正(一致・照応・時制)および跨文境界処理には難がある。
- 自動評価と人間評価の結果、ChatGPT は一部設定で人間レベルの流暢さに近づくまたは超えることがあるが、最小編集制約の下では参照訂正と異なる場合がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。