[論文レビュー] Is K-fold cross validation the best model selection method for Machine Learning?
本論文は、標準的な K-fold クロスバリデーションが偽陽性を過剰に生み出す可能性があると主張し、実際の誤差を上限化し、機械学習における統計的推論を改善するための K-fold Cross Upper Bounding Validation (CUBV) の導入を提案します。特に小規模または異質な神経画像データにおいて。
As a technique that can compactly represent complex patterns, machine learning has significant potential for predictive inference. K-fold cross-validation (CV) is the most common approach to ascertaining the likelihood that a machine learning outcome is generated by chance, and it frequently outperforms conventional hypothesis testing. This improvement uses measures directly obtained from machine learning classifications, such as accuracy, that do not have a parametric description. To approach a frequentist analysis within machine learning pipelines, a permutation test or simple statistics from data partitions (i.e., folds) can be added to estimate confidence intervals. Unfortunately, neither parametric nor non-parametric tests solve the inherent problems of partitioning small sample-size datasets and learning from heterogeneous data sources. The fact that machine learning strongly depends on the learning parameters and the distribution of data across folds recapitulates familiar difficulties around excess false positives and replication. A novel statistical test based on K-fold CV and the Upper Bound of the actual risk (K-fold CUBV) is proposed, where uncertain predictions of machine learning with CV are bounded by the worst case through the evaluation of concentration inequalities. Probably Approximately Correct-Bayesian upper bounds for linear classifiers in combination with K-fold CV are derived and used to estimate the actual risk. The performance with simulated and neuroimaging datasets suggests that K-fold CUBV is a robust criterion for detecting effects and validating accuracy values obtained from machine learning and classical CV schemes, while avoiding excess false positives.
研究の動機と目的
- 標本が小さく異質なデータセットでの仮説検定における標準的なK-fold CVの限界を動機づける。
- CVベースのML分析における実際の誤差を境界づけるための統計的に基づいた方法を提案する。
- 合成データと ADNI/MCI からの実データ・MRI データセットで提案手法を評価する。
- データの異質性とサンプルサイズが ML パイプラインにおける予測推論と誤差境界に与える影響を評価する。
提案手法
- 実際の誤差を経験的CV誤差から境界づけるために concentration inequality を用いる K-fold Cross Upper Bounding Validation (CUBV) を導入する。
- K-fold CV と PAC-Bayesian に触発された上限を組み合わせて misclassification risk の信頼区間を導出する。
- CVベースの上限が特定の閾値を満たす場合に 1−η の確率で帰無仮説を棄却する統計的検定(K-fold CUBV test)を形式化する。
- 異質性を模擬しタイプIエラー制御を評価するために single-cluster および multi-cluster のガウス分布で合成データを使用する。
- ADNI/ADNI-derived features からの実 MRI マルチクラスデータセットへ適用し、所見を検証する。
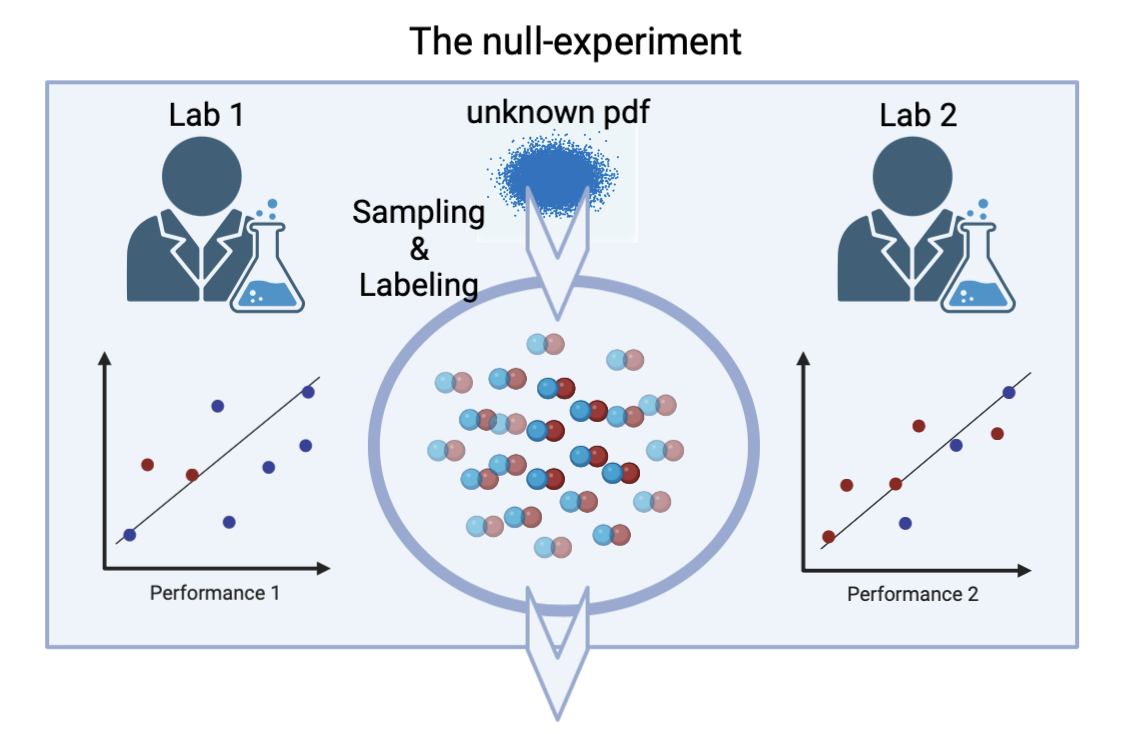
実験結果
リサーチクエスチョン
- RQ1小規模または異質なサンプルにおける K-fold CV ベースの ML は置換検定の下で偽陽性を増大させ得るか?
- RQ2K-fold CUBV アプローチは多様な実験デザインにおいて実際の誤差について有効な上限を提供するか?
- RQ3データの異質性と多クラス構造は神経画像分類タスクにおける予測推論にどのような影響を与えるか?
- RQ4CV と PAC-Bayesian 上限を組み合わせると標準 CV と比較して第I種エラーの制御が改善されるか?
- RQ5提案手法は実際の MRI/MCI 予測タスクに対して実用的でパワフルか?
主な発見
- K-fold CV 単独では、特に小規模サンプルで偽陽性が名目レベルを超えることがある。
- K-fold CUBV は合成データの多サンプル/単一サンプル実験を通じて一貫してタイプIエラーを制御する。
- CUBV アプローチは一部の設定で標準 CV より検出力が低くなるが、異質性下で信頼性のある誤差境界と推論の改善を提供する。
- シミュレーションではデータの複雑性と小さなサンプルサイズが CV の性能変動を高めるが、CUBV はそれを定量化し境界づけるのに役立つ。
- MRI ベースの神経画像データセットへの適用は、最高の ML 精度を検証しつつ過剰な偽陽性を抑制する方法の実現可能性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。