[論文レビュー] Is Mamba Capable of In-Context Learning?
本論文は、選択的な構造化状態空間モデルである Mamba が、シンプルな関数タスクと自然言語処理(NLP)のベンチマークにおいて、インコンテキスト学習(ICL)でトランスフォーマーと同等であることを実証的に示し、長い入力系列に対して効率的な代替手段を提供し得る可能性を示唆している。
State of the art foundation models such as GPT-4 perform surprisingly well at in-context learning (ICL), a variant of meta-learning concerning the learned ability to solve tasks during a neural network forward pass, exploiting contextual information provided as input to the model. This useful ability emerges as a side product of the foundation model's massive pretraining. While transformer models are currently the state of the art in ICL, this work provides empirical evidence that Mamba, a newly proposed state space model which scales better than transformers w.r.t. the input sequence length, has similar ICL capabilities. We evaluated Mamba on tasks involving simple function approximation as well as more complex natural language processing problems. Our results demonstrate that, across both categories of tasks, Mamba closely matches the performance of transformer models for ICL. Further analysis reveals that, like transformers, Mamba appears to solve ICL problems by incrementally optimizing its internal representations. Overall, our work suggests that Mamba can be an efficient alternative to transformers for ICL tasks involving long input sequences. This is an exciting finding in meta-learning and may enable generalizations of in-context learned AutoML algorithms (like TabPFN or Optformer) to long input sequences.
研究の動機と目的
- Mamba が、シンプルな関数クラスと NLP タスクにおいて ICL を実行できるかを示す。
- Mamba の ICL パフォーマンスを、トランスフォーマーのベースラインおよび関連する SSM バリアント(S4)と RWKV と比較する。
- Mamba が ICL を解く機構を調査する。インクリメンタルな内部表現の最適化を含む。
- 文脈長とモデルサイズの増加に伴う Mamba の ICL のスケーラビリティを評価する。
提案手法
- 線形、歪んだ LR、ノイジー LR、ランダムな象限などのシンプルな回帰タスク分布で Mamba およびベースラインを訓練し、同等のパラメータ数で GPT-2/Transformer、S4、RWKV と比較する。
- シンプルな関数クラスに対する ICL パフォーマンスを評価し、同分布内と分布外の一般化を評価する。
- トランスフォーマーと同様の反復的最適化で ICL を解くかを分析する探査戦略を用い、中間表現に対する線形プローブを含む。
- Pile 上でサイズが異なる Mamba 言語モデル(130M 〜 28億パラメータ)を事前学習およびファインチューニングし、Hendel らの NLP タスクにおける RWKV や一般的なトランスフォーマーと ICL パフォーマンスを比較する。
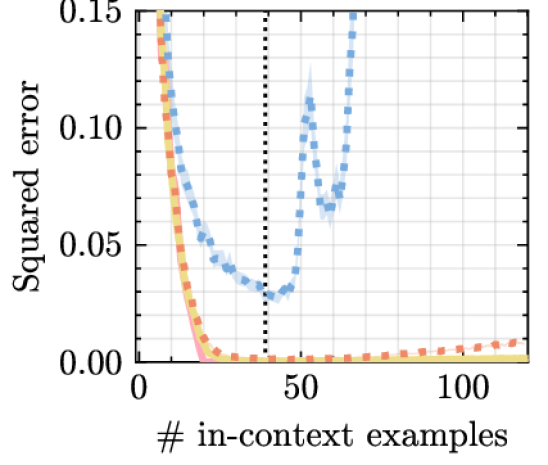
実験結果
リサーチクエスチョン
- RQ1Mamba は単純な回帰タスクにおけるトランスフォーマー並みの ICL パフォーマンスを達成し、長い入力系列へと外挿できるか。
- RQ2Mamba はトランスフォーマーと同様のインクリメンタルな内部表現の最適化による ICL を示すか。
- RQ3NLP ベンチマークにおけるモデルサイズと文脈長の増加に対する Mamba の ICL パフォーマンスはどうスケールするか。
主な発見
- Mamba はいくつかのシンプルな関数クラスと NLP タスクにおいて ICL でトランスフォーマーと同等の性能を示す。
- テスト設定全体で ICL において S4 および RWKV のベースラインを上回る。
- 探査により、Mamba とトランスフォーマーは ICL の過程で解を洗練させる反復的な最適化様式を用いている可能性が示唆される。
- NLP タスクにおける ICL パフォーマンスは、より大きな Mamba モデルとより長い文脈で向上する。
- Mamba は線形回帰でより長い入力へ強い外挿性を示し、NLP ベンチマーク全般で競争力のある精度を維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。