[論文レビュー] JailGuard: A Universal Detection Framework for LLM Prompt-based Attacks
JailGuard は、入力バリアントを生成し応答の発散を測定することでマルチモーダル(画像とテキスト)LLM のジャイルブレイキング攻撃を検出する変異ベースのフレームワークであり、両モダリティで高い検出精度を達成し、ベースラインを上回る。
The systems and software powered by Large Language Models (LLMs) and Multi-Modal LLMs (MLLMs) have played a critical role in numerous scenarios. However, current LLM systems are vulnerable to prompt-based attacks, with jailbreaking attacks enabling the LLM system to generate harmful content, while hijacking attacks manipulate the LLM system to perform attacker-desired tasks, underscoring the necessity for detection tools. Unfortunately, existing detecting approaches are usually tailored to specific attacks, resulting in poor generalization in detecting various attacks across different modalities. To address it, we propose JailGuard, a universal detection framework deployed on top of LLM systems for prompt-based attacks across text and image modalities. JailGuard operates on the principle that attacks are inherently less robust than benign ones. Specifically, JailGuard mutates untrusted inputs to generate variants and leverages the discrepancy of the variants' responses on the target model to distinguish attack samples from benign samples. We implement 18 mutators for text and image inputs and design a mutator combination policy to further improve detection generalization. The evaluation on the dataset containing 15 known attack types suggests that JailGuard achieves the best detection accuracy of 86.14%/82.90% on text and image inputs, outperforming state-of-the-art methods by 11.81%-25.73% and 12.20%-21.40%.
研究の動機と目的
- LLMs および MLLMs の積極的でマルチモーダルなジャイルブレイキング保護の必要性を動機づける。
- 画像とテキストのモダリティで機能する変異ベースの検出フレームワークを提案する。
- 攻撃入力が benign 入力より摂動に対して堅牢性が低いことを示す。
- 初のマルチモーダルジャイルブレイキングデータセットを構築し、JailGuard を最先端の防御と比較評価する。
提案手法
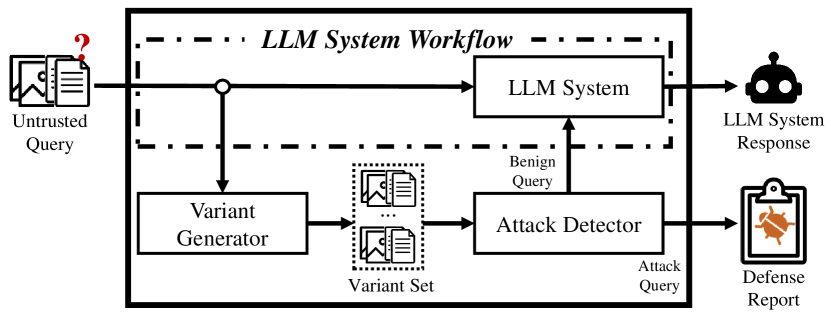
- JailGuard を画像とテキスト入力の変異ベース検出フレームワークとして導入する。
- クエリのバリアントを作成する 19 個の変異器(画像 10 個、テキスト 9 個)からなるバリアント生成器を開発する。
- 効果を高めるために 3 つの高度なテキスト変異器(ターゲット付き置換、ターゲット付き挿入、言い換え)を採用する。
- コサイン類似度に基づく類似度行列と応答分布間の KL 発散を用いてバリアント応答の発散を計算する。
- 閾値付き発散検出器を用いて入力を benign またはジャイルブレイキング攻撃として分類する。

実験結果
リサーチクエスチョン
- RQ1RQ1: JailGuard はテキスト入力と画像入力のジャイルブレイキング攻撃を検出する際にどれくらい有効か。
- RQ2RQ2: JailGuard は異なるタイプのジャイルブレイキング攻撃を検出・防御できるか。
- RQ3RQ3: JailGuard の構成要素(バリアント生成器と攻撃検出器)はどれくらい有効か。
- RQ4RQ4: 生成されるバリアントの数は検出性能にどう影響するか。
主な発見
| Method | Accuracy (%) | Recall (%) |
|---|---|---|
| Random Mask | 75.00 | 75.00 |
| Gaussian Blur | 82.50 | 76.25 |
| Horizontal Flip | 73.75 | 81.25 |
| Vertical Flip | 85.00 | 78.75 |
| Crop and Resize | 78.13 | 81.25 |
| Random Grayscale | 80.63 | 77.50 |
| Random Rotation | 89.38 | 78.75 |
| Colorjitter | 85.00 | 80.00 |
| Random Solarization | 89.38 | 80.00 |
| Random Posterization | 82.50 | 70.00 |
| Average | 82.13 | 77.88 |
| Baseline Content Detector | 55.56 | 29.17 |
| SmoothLLM-Insert | 70.14 | 41.67 |
| SmoothLLM-Swap | 66.67 | 34.72 |
| SmoothLLM-Patch | 70.14 | 41.67 |
| Average Baselines | 65.62 | 36.81 |
| Random Replacement | 77.78 | 75.00 |
| Random Insertion | 79.17 | 77.78 |
| Random Deletion | 79.17 | 76.39 |
| Synonym Replacement | 73.61 | 84.72 |
| Punctuation Insertion | 75.00 | 70.83 |
| Translation | 78.47 | 84.72 |
| Targeted Replacement | 82.64 | 88.89 |
| Targeted Insertion | 84.03 | 81.94 |
| Rephrasing | 85.42 | 91.67 |
| Average Text | 79.48 | 81.33 |
- JailGuard は画像入力で平均検出精度 82.13%、テキスト入力で 79.48% を達成(バリアントごと)。
- JailGuard のリコールの平均は 画像 77.88%、テキスト 81.33% で、偽陰性が低い強力な攻撃検出を示す。
- テキストデータでは高度な変異器(ターゲット付き置換、ターゲット付き挿入、言い換え)がベースラインを上回り、言い換えは 85.42% の精度と 91.67% のリコールを達成。
- 画像データでは一部の変異器が最大 89.38% の精度と 80.00–81.25% のリコールを達成し、同等の画像ベースラインが欠如している状況を凌駕。
- JailGuard はテキスト入力での検出精度で最先端のベースラインより最大 15.28% 上回る。
- 防御評価を行うための初のマルチモーダルジャイルブレイキングデータセット(テキストと画像の計 304 件)を構築。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。