[論文レビュー] Jasper: An End-to-End Convolutional Neural Acoustic Model
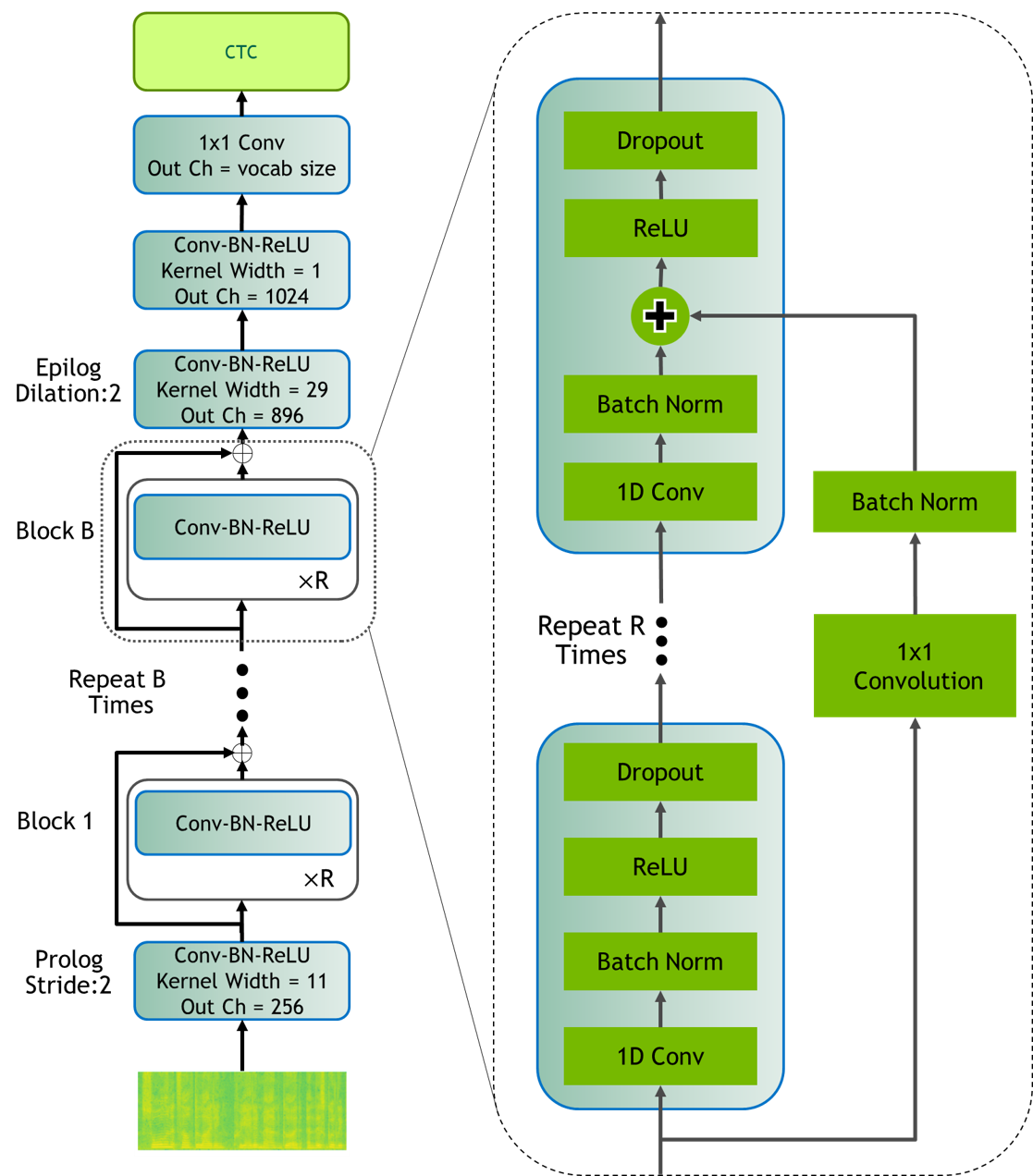
Jasper は 1D 畳み込み、バッチ正規化、 ReLU、ドロップアウト、残差接続を用いたエンドツーエンドの畳み込みニューラル音響モデルで、Transformer-XL 言語モデルとともに LibriSpeech の最先端結果を達成し、test-clean で 2.95% WER。
In this paper, we report state-of-the-art results on LibriSpeech among end-to-end speech recognition models without any external training data. Our model, Jasper, uses only 1D convolutions, batch normalization, ReLU, dropout, and residual connections. To improve training, we further introduce a new layer-wise optimizer called NovoGrad. Through experiments, we demonstrate that the proposed deep architecture performs as well or better than more complex choices. Our deepest Jasper variant uses 54 convolutional layers. With this architecture, we achieve 2.95% WER using a beam-search decoder with an external neural language model and 3.86% WER with a greedy decoder on LibriSpeech test-clean. We also report competitive results on the Wall Street Journal and the Hub5'00 conversational evaluation datasets.
研究の動機と目的
- LibriSpeech および他 benchmarks でエンドツーエンドで非エンドツーエンド手法と同等以上を満たす、計算効率の高いエンドツーエンド CNN 音響モデル ASR の実証。
- very deep 1D-CNN ベースの ASR モデルを可能にするアーキテクチャ選択(活性化関数、正規化、残差)とオプティマイザ戦略の調査。
- エンドツーエンド Jasper の性能に外部言語モデル(ニューラルおよびN-gram)を組み込む効果を示す。
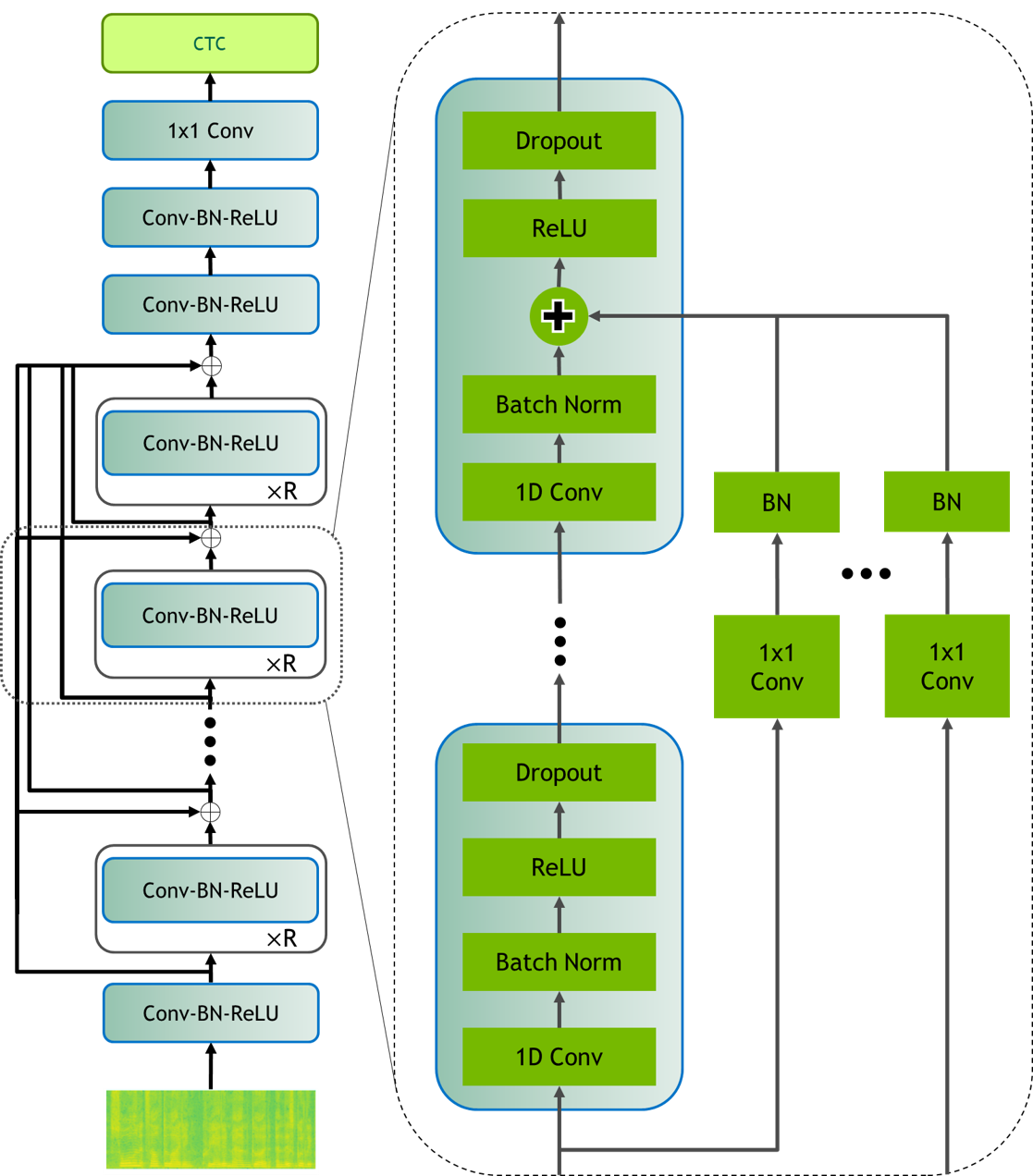
- Dense Residual を含む残差接続のバリアントを提案・評価し、非常に深いネットワークの訓練を可能にする。
- 再現可能な訓練設定とアブレーションを提供し、 Jasper をエンドツーエンド CNN ベースの ASR の強力なベースラインとして確立。
提案手法
- Residual 接続を備えた 1D-畳み込みブロックのスタックを使用する(Jasper B x R モデル)。
- 正規化(バッチ正規化、レイヤー正規化、ウェイト正規化)と活性化(ReLU、cReLU、lReLU、GAU/GLU)を用いて効果的な組み合わせを特定。
- NovoGrad オプティマイザ(層ごとの二次モーメント推定)を導入し、訓練の安定性を改善しメモリを削減。
- Dense Residual を含む残差トポロジを評価し、DenseNet/DenseRNet 内ブロック接続と比較;より深いモデルには Dense Residual を選択。
- ビームサーチ(幅 2048)を用いて音響 + 単語レベル N-gram LM でデコードし、Transformer-XL ニューラル LM によるリスコアリングを実施;貪欲法デコード結果も報告。
- SGD ミomentum または NovoGrad を用いて Jasper バリアントを最大 54 層の畳み込み(333M パラメータ)訓練;LM 実験で Spec 増強のようなマスキングを適用。
実験結果
リサーチクエスチョン
- RQ1Purely 1D-convolutional end-to-end acoustic model が LibriSpeech で外部学習データなしに最先端の結果を達成できるか。
- RQ2非常に深い 1D CNN ASR モデルを可能にする正規化、活性化、残差接続の構成はどれか。
- RQ3NovoGrad が訓練安定性と WER に与える影響は SGD と比べてどうか。
- RQ4LibriSpeech に対するエンドツーエンド Jasper の性能に外部言語モデル(N-gram および Transformer-XL)を組み込むとどうなるか。
- RQ5Dense Residual/DenseNet 風の接続性は、古典的な残差よりも深い Jasper モデルに有利か。
主な発見
| モデル | E2E | LM | dev-clean | dev-other | test-clean | test-other |
|---|---|---|---|---|---|---|
| CAPIO (single) | N | RNN | 3.02 | 8.28 | 3.56 | 8.58 |
| pFSMN-Chain | N | RNN | 2.56 | 7.47 | 2.97 | 7.50 |
| DeepSpeech2 | Y | RNN | - | - | 5.33 | 13.25 |
| Deep bLSTM w/ attention | Y | LSTM | 3.54 | 11.52 | 3.82 | 12.76 |
| wav2letter++ | Y | ConvLM | 3.16 | 10.05 | 3.44 | 11.24 |
| Jasper DR 10x5 | Y | RNN | - | - | 2.50 | 5.80 |
| Jasper DR 10x5 | Y | 4-gram | 2.89 | 9.53 | 3.34 | 9.62 |
| Jasper DR 10x5 | Y | Transformer-XL | 2.68 | 8.62 | 2.95 | 8.79 |
| Jasper DR 10x5 + Time/Freq Masks | Y | Transformer-XL | 2.62 | 7.61 | 2.84 | 7.84 |
- Jasper は LibriSpeech の test-clean で最先端、end-to-end モデル間で競争力のある結果を示す(test-clean で Transformer-XL LM 使用時 2.95% WER)。
- 大規模な Jasper モデルでは ReLU を用いたバッチ正規化が他の正規化・活性化の組み合わせより優れており、非常に深いネットワークの収束には残差接続が必要。
- NovoGrad は 10x5 Jasper DR モデルで dev-clean WER を 4.00% から 3.64% に改善し、相対改善 9% を示す。
- Dense Residual 接続は他の dense/接続法と同程度の性能を発揮しつつ成長因子を抑え、非常に深い Jasper ネットワークの訓練を容易にする。
- 外部言語モデル(N-gram および Transformer-XL)をビーム探索とリスコアリングに使用すると LibriSpeech の WER が著しく改善され、Transformer-XL は Jasper DR 10x5 の test-clean WER を 2.95% に達成。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。