[論文レビュー] Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
この論文は、TriviaQA のジャッジとしての LLM を体系的に研究し、人間の判断と語彙的ベースラインと比較しています。わずかなジャッジのみが人間と良く一致し、コーエンのカッパは百分率合意よりも良い整合性指標であり、いくつかの安価な方法が受験者モデルのランキングで同等以上の成績を示すことが分かります。
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges, focusing on a clean scenario in which inter-human agreement is high. Investigating thirteen judge models of different model sizes and families, judging answers of nine different 'examtaker models' - both base and instruction-tuned - we find that only the best (and largest) models achieve reasonable alignment with humans. However, they are still quite far behind inter-human agreement and their assigned scores may still differ with up to 5 points from human-assigned scores. In terms of their ranking of the nine exam-taker models, instead, also smaller models and even the lexical metric contains may provide a reasonable signal. Through error analysis and other studies, we identify vulnerabilities in judge models, such as their sensitivity to prompt complexity and length, and a tendency toward leniency. The fact that even the best judges differ from humans in this comparatively simple setup suggest that caution may be wise when using judges in more complex setups. Lastly, our research rediscovers the importance of using alignment metrics beyond simple percent alignment, showing that judges with high percent agreement can still assign vastly different scores.
研究の動機と目的
- 知識ベンチマーク(TriviaQA)に対する LLM ジャッジと人間の判断の整合性を評価する。
- ベースおよび指示で調整されたバリアントを含む、サイズ別・ファミリー別の複数のジャッジモデルを比較する。
- LLM ベースのジャッジにおける偏り、誤り、信頼性の問題を特定する。
- 安価または専門のジャッジモデルが、大規模なジャッジと同等か、受験者モデルのランキングで上回るかを評価する。
提案手法
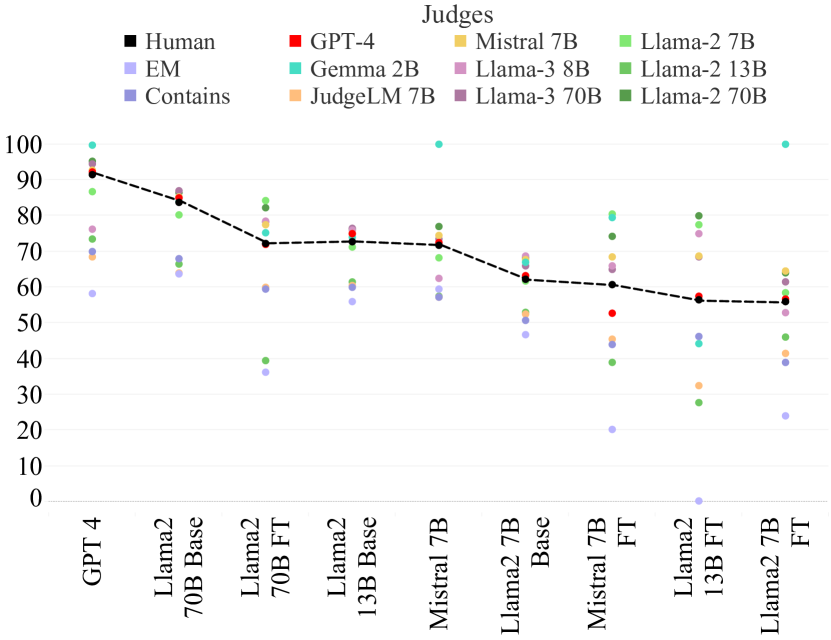
- TriviaQA バリデーションセット 400 問を用いて手動の受験者注釈を作成;9 つのジャッジモデルが9 つの受験者モデルを評価する。
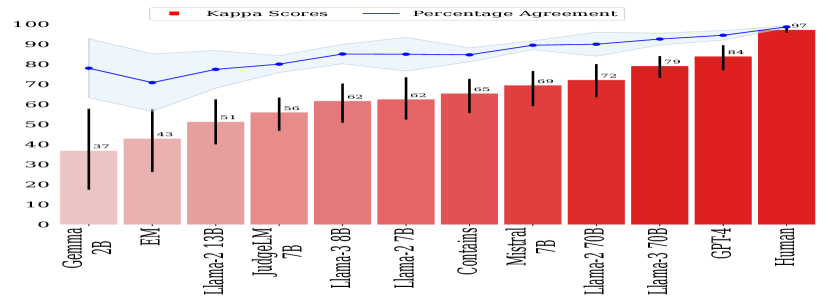
- ジャッジ出力を人間の判断と百分比合意およびコーエンのカッパで比較する。
- 基線語彙メトリクスには正解一致(EM)と含有一致(contains)を含む。
- 9 つの受験者モデルにわたるスピアマンの rho を使って人間の判断との順位相関を調べる。
- エラーペアの種類、プロンプトの変動効果、およびダミーや幻覚的な回答に対する頑健性を分析する。
実験結果
リサーチクエスチョン
- RQ1TriviaQA の質問に対して、さまざまな LLM がジャッジとして人間の判断とどれだけ一致するか?
- RQ2コーエンのカッパは LLM ジャッジにとって百分率合意より信頼できる整合性指標を提供するか?
- RQ3ランキングの観点で受験者モデルを最もよく区別するジャッジモデルはどれで、整合性のコストはどの程度か?
- RQ4ジャッジに影響を与える体系的な偏りや失敗モードは何か(例:プロンプトの長さ、寛大さ、非情報的な回答への感受性)?
主な発見
- GPT-4 Turbo と Llama-3 70B は人間と非常に良く整合しているが(カッパ 84 と 79、いずれも人間の整合性レベル 96 を下回る)。
- 包含(Contains)は複数のジャッジで EM よりカッパを高くするが、EM は全体として最悪の性能を示すことが多く、百分比合意は誤解を招くことがある。
- Contains、JudgeLM 7B、および GPT-4 Turbo/Llama-3 70B はランキング精度が異なる;いくつかの安価な方法は整合性が低くてもランキング精度で一致・上回ることがある。
- ジャッジモデルは未定義または過度に寛大な判断に苦労し、「Yes」や「Sure」 のような非情報的回答に惑わせやすい。
- Recall は人間との整合性が高いほど改善する傾向があり(r^2 ≈ 0.98)、一方で Precision には整合性と明確な傾向が見られない。
- より詳細なガイドラインを含むプロンプトはトップパフォーマンスのジャッジにだけ効果がある;多くのジャッジはプロンプト設計と参照順に敏感である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。