[論文レビュー] Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
この論文は層間線形マッピングを学習して隠れたトランスフォーマー表現を転送し、最終層出力のより良い近似を実現するとともに、早期終了とサブモジュールの線形近似の効率を向上させます。
Transformer-based language models create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, using linear transformations. This approximation far exceeds the prevailing practice of inspecting hidden representations from all layers, in the space of the final layer. Moreover, in the context of language modeling, our method produces more accurate predictions from hidden layers, across various model scales, architectures, and data distributions. This allows "peeking" into intermediate representations, showing that GPT-2 and BERT often predict the final output already in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change. Our code and learned mappings are publicly available at https://github.com/sashayd/mat.
研究の動機と目的
- intermediate transformer representations を用いる interpretability と efficiency gains をMotivateする。
- 任意の前の層から後の層へ hidden states を変換する軽量な線形マッピング(mat)を提案する。
- mat がGPT-2とBERTの複数データソースに対して最終層表現と予測をどれだけ近似できるかを評価する。
- 早期終了や attention、FFN、層正規化などのサブモジュールの近似における実用的利益を示す。
提案手法
- ell < ell' の任意の層ペアに対して、隠れ状態のペアをモデルを通してシーケンスを実行して収集し、回帰損失を最小化する d_h x d_h 行列 A_{ell',ell} を学習する。
- mat_{ell→ell'} を、表現をそのまま伝播させる単なるアイデンティティマッピングのベースラインと比較する。
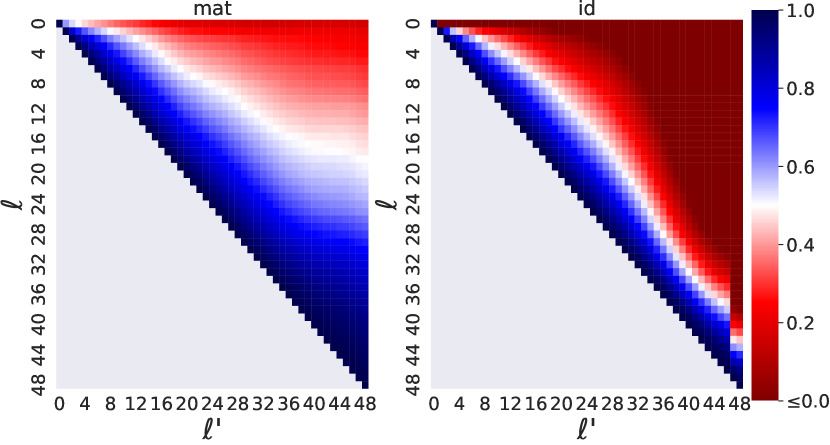
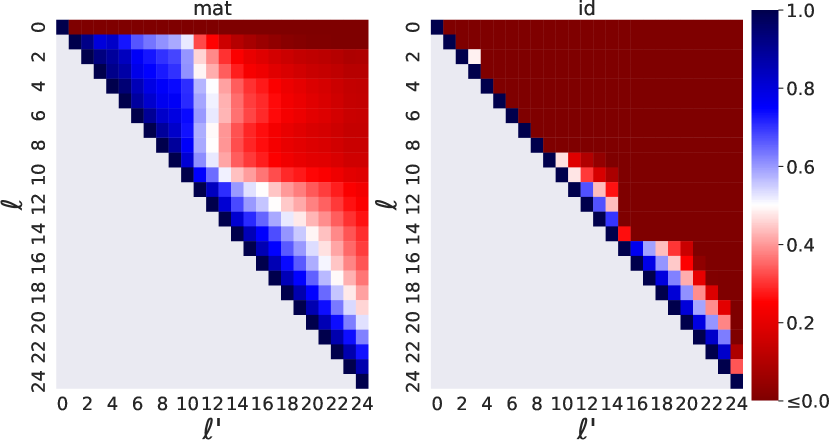
- mat(h^{ell}) と真の h^{ell'} との座標ごとの R^2 を用いて近似品質を測定する。
- next-token および masked-token 予測タスクに学習済みマッピングを適用し、Precision@k および surprisal で予測整合性を評価する。
- 線形ショートカットを拡張してサブモジュール(attention、FFN、layer norm)を線形近似で置換し、予測精度への影響を評価する。
- mat の早期終了での有用性を示すため、アイデンティティマッピングを mat に置換してダイナミック終了決定を適用し、計算節約を比較する。
実験結果
リサーチクエスチョン
- RQ1 トランスフォーマー層間の単純な線形マッピングは、一般的なアイデンティティ伝搬よりも最終層表現のより正確な代替となり得るか。
- RQ2 このようなマッピングは、次のトークン予測およびマスク済みトークンタスクにおけるモデルの予測分布をどれだけ保持できるか。
- RQ3 線形ショートカットは早期終了や attention、FFN、layer norm の置換において意味のある効率化を実現できるか。
主な発見
- Mat は、特にBERTにおいてアイデンティティベースラインよりも一貫して高いR^2スコアを達成する(アイデンティティは層間でのマッピングが機能しない場合がある)。
- 言語モデルタスクでは mat は id よりもPredictioin@k を改善し、Surprisal を低下させる。特に初期層で顕著な改善(例: GPT-2 の層44まで大幅な正確性向上)を示す。
- 早期終了で mat を用いると、従来より多くの層を節約可能(例:GPT-2 で7.9%、BERT で5.4% の層を節約して95%の正確度に到達)した。
- 初期表現はすでに最終予測を意味のある程度まで符号化していることを示す。初期層でも非自明な予測整合性(トップ1 Precision の 0.28–0.45 など)が観察される。
- サブモジュールを線形ショートカットで近似する場合、attention が最も線形置換に寛容であり、FFN と layer norm はより敏感だが、多くのケースで線形近似が可能。
- サブモジュールを線形ショートカットで置換しても、いくつかの層で壊滅的な損失を伴わずに実行できる場合があり、並列計算の利点が示唆される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。