[論文レビュー] Knowledge Diffusion for Distillation
DiffKDは、教師特徴量で訓練された拡散モデルを用いて学生特徴量をノイズ除去し、教師-学生のギャップを埋め、ビジョンタスク全体でのより効果的な知識蒸留を実現します。
The representation gap between teacher and student is an emerging topic in knowledge distillation (KD). To reduce the gap and improve the performance, current methods often resort to complicated training schemes, loss functions, and feature alignments, which are task-specific and feature-specific. In this paper, we state that the essence of these methods is to discard the noisy information and distill the valuable information in the feature, and propose a novel KD method dubbed DiffKD, to explicitly denoise and match features using diffusion models. Our approach is based on the observation that student features typically contain more noises than teacher features due to the smaller capacity of student model. To address this, we propose to denoise student features using a diffusion model trained by teacher features. This allows us to perform better distillation between the refined clean feature and teacher feature. Additionally, we introduce a light-weight diffusion model with a linear autoencoder to reduce the computation cost and an adaptive noise matching module to improve the denoising performance. Extensive experiments demonstrate that DiffKD is effective across various types of features and achieves state-of-the-art performance consistently on image classification, object detection, and semantic segmentation tasks. Code is available at https://github.com/hunto/DiffKD.
研究の動機と目的
- キャパシティの差によるKDにおける教師と学生の表現ギャップを動機づけ、対処する。
- 学生特徴量から価値ある情報を抽出する拡散ベースのノイズ除去モジュールを提案する。
- 計算量を削減するために線形オートエンコーダを備えた軽量拡散モデルを導入する。
- 初期の拡散ノイズレベルを揃える適応的ノイズマッチング機構を追加する。
- 分類・検出・セグメンテーションタスク全体で手法の有効性を示す。
提案手法
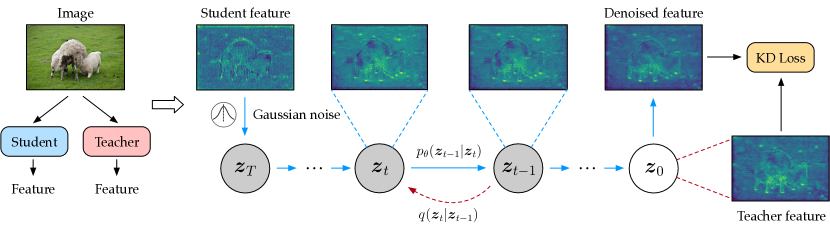
- 学生特徴量を教師特徴量のノイズ付き版とみなし、教師特徴量上で拡散モデルを訓練して学生特徴量をノイズ除去する。
- ノイズ除去された学生特徴量を用いて、標準的なKD損失で教師特徴量に対して蒸留を行う。
- 特徴表現を圧縮するため、2つのボトルネックブロックと線形オートエンコーダを備えた軽量拡散アーキテクチャを組み込む。
- 初期化のために適切なガウスノイズを推定して注入する適応的ノイズマッチングモジュールを導入する。
- 拡散損失と蒸留損失には標準的な距離(MSE, KL)を用い、高度なKD損失(例: DIST, DKD)を利用するオプションを用意する。
- 全パイプラインを複合損失で最適化する:Ltrain = Ltask + lambda1 Ldiff + lambda2 Lae + lambda3 Ldiffkd。
実験結果
リサーチクエスチョン
- RQ1拡散モデルをどのように活用してKDのために教師と学生の特徴量をノイズ除去し、整合させることができるか。
- RQ2学生特徴量のノイズ除去は、タスク間での直接的な特徴量マッチングよりも知識移転を改善するのか。
- RQ3軽量拡散モデルと適応的ノイズマッチングは、過度なコストをかけずに実用的な利点を達成できるか。
- RQ4DiffKDアプローチは、特徴タイプ(中間特徴量、ロジット)やタスク(分類、検出、セグメンテーション)全般に汎用か。
主な発見
- DiffKDはタスクを横断して一貫した最先端の利得をもたらし、例としてImageNetでMobileNetV1学生とResNet-50教師の組み合わせで73.62% top-1精度。
- より強力な教師設定では、Swin-T/Swin-L や ResNet系などのモデル対で従来のKD法を上回る。
- DiffKDは複数のベースラインに対して検出とセグメンテーションのベンチマークを改善し、単純なKD損失(MSE、KL)でも有効なまま。
- 線形オートエンコーダを備えた軽量拡散モデルは、FLOPsを大幅に削減しつつ蒸留性能を維持または向上させる。
- Adaptive noise matching (ANM)は初期拡散ノイズを学生特徴量に合わせて整合させることでノイズ除去を改善する。
- アブレーションの結果、特徴とロジットのDiffKDを組み合わせると最高の性能を達成することが示され、(例:ある設定で73.62%)。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。