[論文レビュー] Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
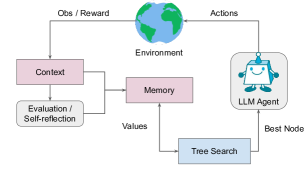
LATSはモンテカルロ木探索フレームワーク内でLMの要素をエージェント、価値関数、オプティマイザとして扱い、外部からのフィードバックと自己反省を用いて、言語モデルを用いた計画・行動・推論を統合する。さまざまなタスクで意思決定を改善する。
While language models (LMs) have shown potential across a range of decision-making tasks, their reliance on simple acting processes limits their broad deployment as autonomous agents. In this paper, we introduce Language Agent Tree Search (LATS) -- the first general framework that synergizes the capabilities of LMs in reasoning, acting, and planning. By leveraging the in-context learning ability of LMs, we integrate Monte Carlo Tree Search into LATS to enable LMs as agents, along with LM-powered value functions and self-reflections for proficient exploration and enhanced decision-making. A key feature of our approach is the incorporation of an environment for external feedback, which offers a more deliberate and adaptive problem-solving mechanism that surpasses the constraints of existing techniques. Our experimental evaluation across diverse domains, including programming, interactive question-answering (QA), web navigation, and math, validates the effectiveness and generality of LATS in decision-making while maintaining competitive or improved reasoning performance. Notably, LATS achieves state-of-the-art pass@1 accuracy (92.7%) for programming on HumanEval with GPT-4 and demonstrates gradient-free performance (average score of 75.9) comparable to gradient-based fine-tuning for web navigation on WebShop with GPT-3.5. Code can be found at https://github.com/lapisrocks/LanguageAgentTreeSearch
研究の動機と目的
- 自律的なLMエージェントが外部環境で計画・行動・推論を行える必要性を動機づける。
- 環境フィードバックと自己反省を活用する一般的なLMベースのモンテカルロ木探索フレームワークであるLATSを提案する。
- プログラミング、オープンドメインQA、ウェブナビゲーションなど多様な領域でLATSを実証し、汎用性を示す。
- 外部フィードバックと統合された推論-行動-計画ループが、従来の prompting 手法より性能を向上させることを示す。
提案手法
- 事前学習済みのLMをMCTS風の探索内でLMエージェント、価値関数、オプティマイザとして再利用する。
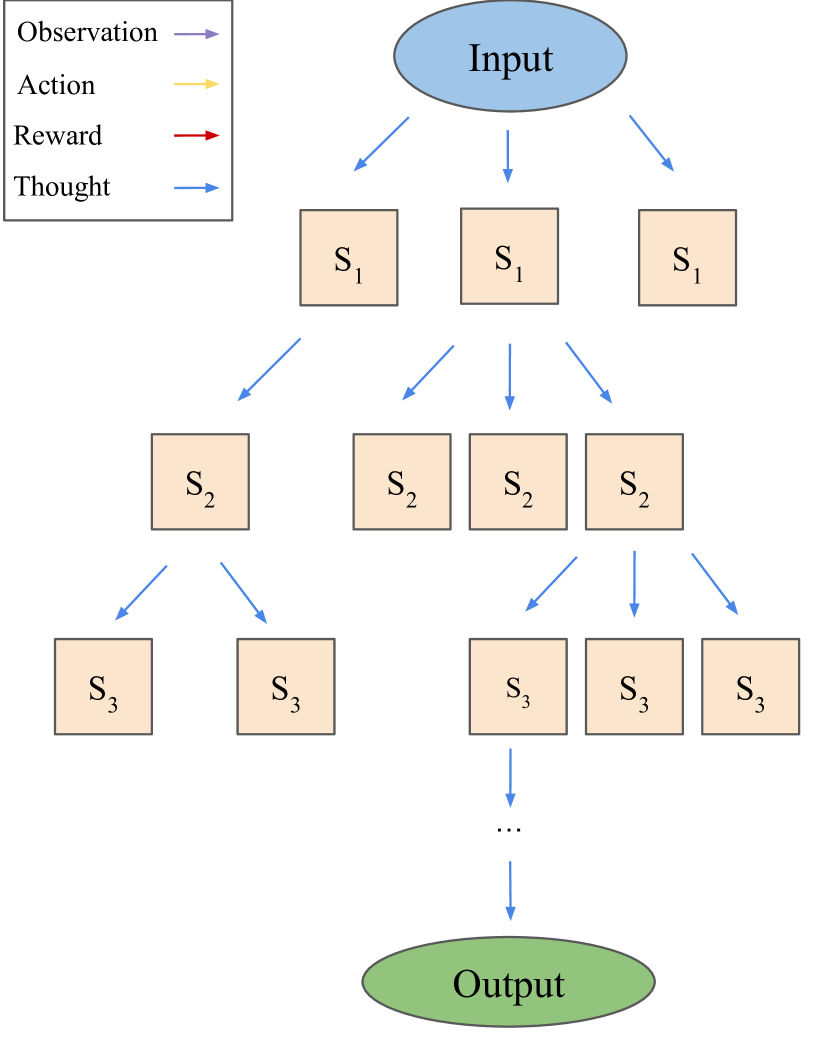
- ノードを [x, a1..i, o1..i] と定義し、標準的なMCTSの選択・展開・評価・シミュレーション・逆伝播を、行動を導くLMプロンプトと価値推定を用いて実行する。
- 展開時にLMがn個の行動を生成し、葉ノードを価値関数としてスコア付けして、熟考的な軌道構築を可能にする。
- 環境観察による外部フィードバックと、失敗した軌道を注釈付けしてインコンテキスト学習のために格納する自己反省モジュールを組み込む。
- 将来の試行を意味的な指針で補強する反省ステップを含め、スカラー報酬信号を豊かにする。
- 推論と行動を現実の外部ツールやAPIと連携させる(ReActのように)ことで、外部環境での行動と推論の橋渡しを行う。
- プログラミング(GPT-4によるHumanEval)、HotPotQA、WebShopでLATSを評価し、多様性と性能向上を示す。
実験結果
リサーチクエスチョン
- RQ1LMベースのモンテカルロ木探索フレームワークは、意思決定タスクにおいて推論・計画・行動を統合できるか?
- RQ2外部環境フィードバックとLM生成の反省を活用することで、ReAct・CoT・ToT・RAPなど従来の prompting 手法を超える性能向上が得られるか?
- RQ3LATSはプログラミング・マルチホップQA・ウェブナビゲーションを要する領域でどの程度機能するか?
- RQ4展開幅nと軌道サンプル数kを変えることが、性能と計算量にどのような影響を及ぼすか?
- RQ5自己反省はLM主導の計画・行動における性能向上にどの程度寄与するか?
主な発見
- LATSはGPT-4を用いたHumanEvalプログラミングで94.4%のPass@1を達成し、その設定で最先端を確立した。
- GPT-3.5を用いたWebShopでLATSは平均スコア75.9を達成し、基準より優れた探索ベースの計画を示した。
- HotPotQAでは、LATSが評価対象の手法の中で最も高い actingベースのEM(0.61)を達成し、推論では0.61(ベースラインの0.60–0.64レンジと競合)。
- LATSはHotPotQAのサンプリング予算全体でReActを上回り、ノード展開数nが大きいほど一貫した改善を示した。
- 自己反省はパフォーマンスに適度な寄与を示し、一部のアブレーションでは約0.05ポイントの向上に留まり、意味的フィードバックがスカラー逆伝播を超えた付加価値を提供することを示唆。
- アブレーションでは、LMヒューリスティック、反省、DFS設定のいずれかを除去すると性能が低下することが示され、LATS全体の設計の重要性を裏付けている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。