[論文レビュー] Language agents achieve superhuman synthesis of scientific knowledge
PaperQA2は先端的な言語モデルエージェントで、文献検索と要約タスクにおいて博士レベルの人間と同等かそれを上回り、LitQA2で他を上回り、ContraCrowとWikiCrowの評価を用いた大規模な矛盾検出を可能にする。
Language models are known to hallucinate incorrect information, and it is unclear if they are sufficiently accurate and reliable for use in scientific research. We developed a rigorous human-AI comparison methodology to evaluate language model agents on real-world literature search tasks covering information retrieval, summarization, and contradiction detection tasks. We show that PaperQA2, a frontier language model agent optimized for improved factuality, matches or exceeds subject matter expert performance on three realistic literature research tasks without any restrictions on humans (i.e., full access to internet, search tools, and time). PaperQA2 writes cited, Wikipedia-style summaries of scientific topics that are significantly more accurate than existing, human-written Wikipedia articles. We also introduce a hard benchmark for scientific literature research called LitQA2 that guided design of PaperQA2, leading to it exceeding human performance. Finally, we apply PaperQA2 to identify contradictions within the scientific literature, an important scientific task that is challenging for humans. PaperQA2 identifies 2.34 +/- 1.99 contradictions per paper in a random subset of biology papers, of which 70% are validated by human experts. These results demonstrate that language model agents are now capable of exceeding domain experts across meaningful tasks on scientific literature.
研究の動機と目的
- 信頼できる、事実に基づく科学文献の検索と統合のためのAIの使用を動機づける。
- 取得、要約、矛盾検出タスク全体にわたる厳密な人間–AI比較フレームワークの開発と検証。
- モデルとシステム設計を導くデータセット(LitQA2、ContraDetect)の作成とベンチマーク。
- 生物学文献の事実性を向上させ、矛盾を検出するスケーラブルなツール(WikiCrow、ContraCrow)を実証。
提案手法
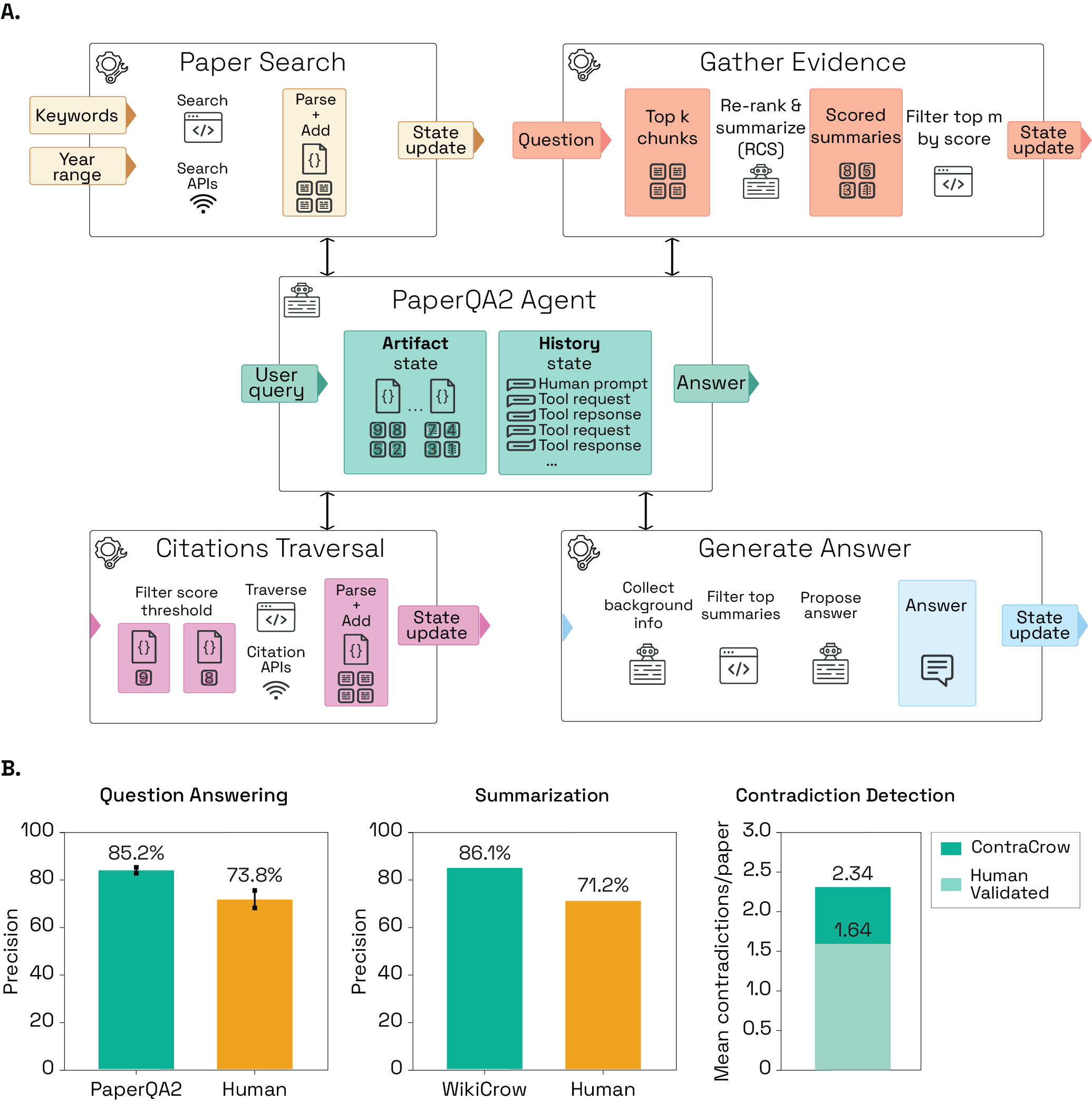
- PaperQA2を開発する。 Paper Search、Gather Evidence、Generate Answer、Citation Traversalという多段ツールセットを備えた検索強化生成エージェント。
- RCS(文脈要約)とエビデンスのトップkランク付けで回答を根拠づけ、関連性と事実性を向上。
- DOIsを用いてソースを一致させる非要約情報に焦点を当てた248問の選択肢型取得問題としてLitQA2を作成。
- LitQA2指標(精度、正確性、再現率)を用いてPaperQA2を人間の専門家や他のシステムと比較。
- WikiCrowをWikipedia風の遺伝子記事生成に適用し、事実性を人間のWikipedia記事と比較して評価。
- ContraCrowを構築し、医学・生物学文献の主張を抽出し、矛盾検出プロンプトとLikert尺度評価によって文献と照らして矛盾を検出。
実験結果
リサーチクエスチョン
- RQ1実世界の科学文献検索タスクで言語モデルエージェントは人間並びに超人レベルの性能を達成できるか。
- RQ2取得強化生成エージェントは要約タスクで人間作成の科学要約と比較してどの程度の性能を示すか。
- RQ3AIシステムはスケールして科学文献の矛盾を体系的に特定できるか、専門家評価とどのように比較されるか。
- RQ4設計選択(RCS、引用 traversal、文脈深度)は事実性と取得精度にどのように影響するか。
- RQ5AI由来の矛盾は生物学文献の人間判断とどのように比較されるか。
主な発見
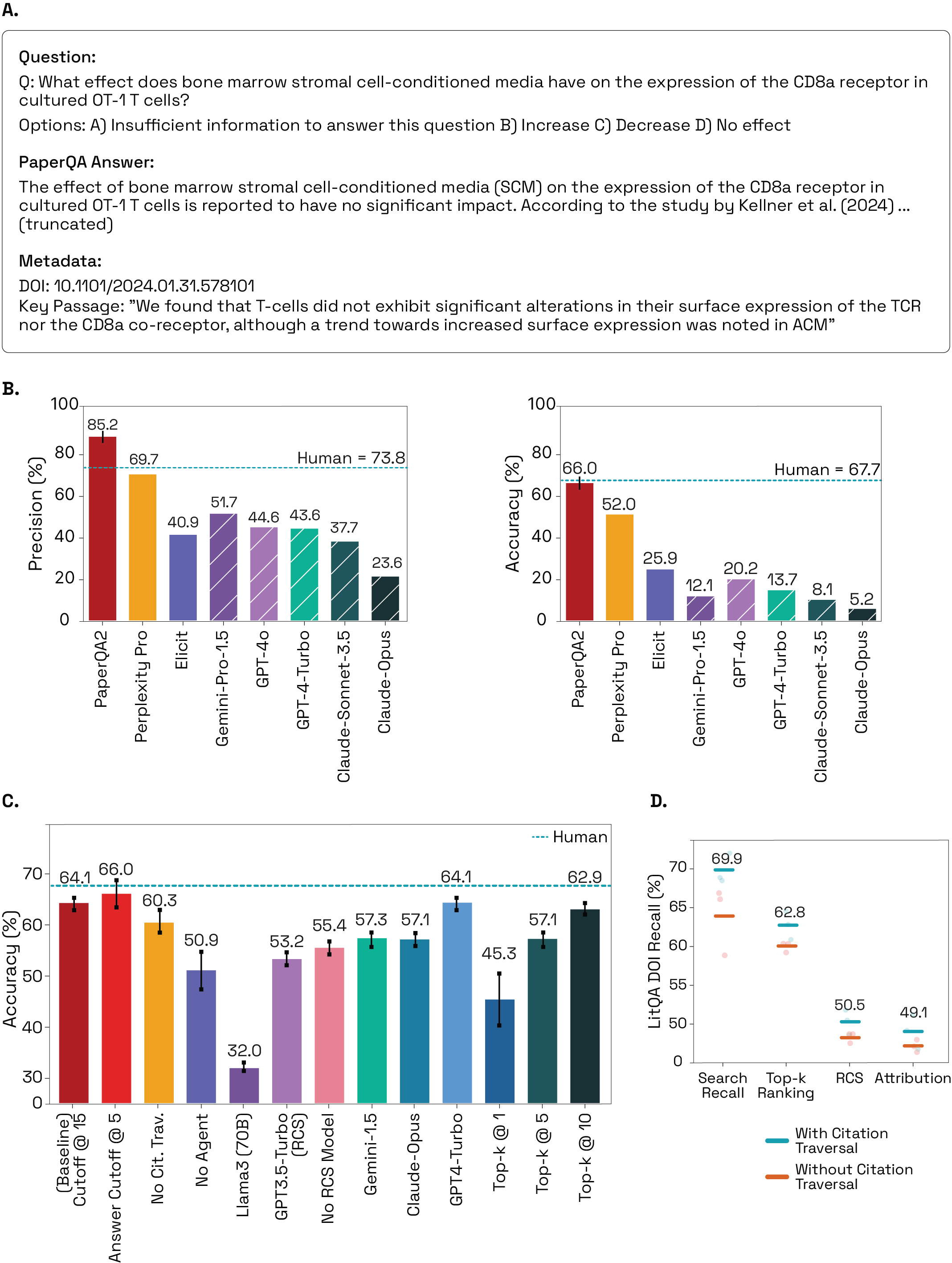
- PaperQA2はLitQA2において精度85.2%、正確性66.0%を達成し、人間が注釈したベースラインを超える精度を示し、正確性は人間と同等である。
- 人間はLitQA2で精度73.8%、正確性67.7%を達成したが、PaperQA2は統計的に人間の精度を超えており(p=0.0036)、正確性には有意差がない(p=0.66)。
- 深い文脈要約(RCS)と引用 traversalはLitQA2の各段階で取得精度とDOIリコールを大幅に向上させる。
- WikiCrowはWikipediaより未出典率が低い(3.5%)240の記事を生成し、Wikipediaの精度(86.1%)はWikipediaの71.2%を上回り、平均的に長い。
- ContraCrowは生物学論文あたり平均2.34±1.99の矛盾を検出(n=93)、評価された矛盾の70%が人間専門家によって妥当性が確認された。
- ContraDetectベースの評価はROC AUC0.842を示し、矛盾検出の閾値8で精度88%を達成。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。