[論文レビュー] Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game
要旨:本論文は、大規模言語モデルと強化学習を組み合わせてWerewolf用の戦略的言語エージェントを構築する枠組みを提案し、内在的バイアスと隠れ情報の推定に対処し、ベースラインを含む人間レベルのプレイを含む性能を上回ることを示す。
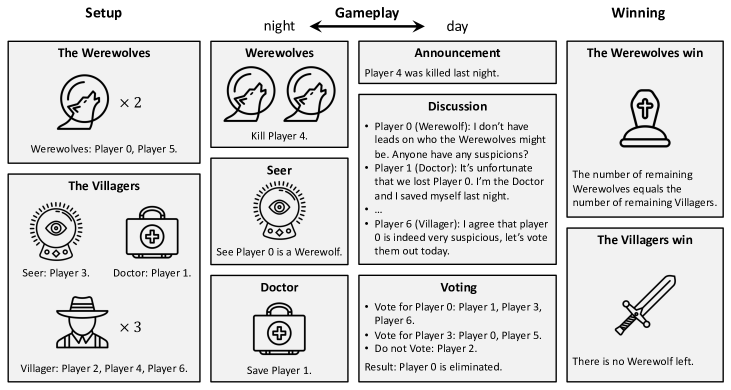
Agents built with large language models (LLMs) have shown great potential across a wide range of domains. However, in complex decision-making tasks, pure LLM-based agents tend to exhibit intrinsic bias in their choice of actions, which is inherited from the model's training data and results in suboptimal performance. To develop strategic language agents, i.e., agents that generate flexible language actions and possess strong decision-making abilities, we propose a novel framework that powers LLM-based agents with reinforcement learning (RL). We consider Werewolf, a popular social deduction game, as a challenging testbed that emphasizes versatile communication and strategic gameplay. To mitigate the intrinsic bias in language actions, our agents use an LLM to perform deductive reasoning and generate a diverse set of action candidates. Then an RL policy trained to optimize the decision-making ability chooses an action from the candidates to play in the game. Extensive experiments show that our agents overcome the intrinsic bias and outperform existing LLM-based agents in the Werewolf game. We also conduct human-agent experiments and find that our agents achieve human-level performance and demonstrate strong strategic play.
研究の動機と目的
- 社会的推理ゲームでの複雑な意思決定を可能にする戦略的言語エージェントの開発を動機づける。
- 多様なアクション生成と強化学習を通じて純粋なLLMベースエージェントの内在的バイアスを解消する。
- 隠れ役割推定を可能にして欺瞞情報を扱い、以後の意思決定を改善する。
提案手法
- 隠れ役割推定:LLMを用いて観察を整理し、真実と欺瞞を分類し、属性(役割、信頼性、推論、証拠)を生成する。
- 多様なアクション生成:バニラ prompting または反復 prompting によって複数のアクション候補(N)を生成し、アクションバイアスを減らし戦略的多様性を向上させる。
- 集団ベースのRL訓練:LLMの埋め込みから得られる自己注意型ネットワークに入力して、言語アクション候補の中から選択する軽量ポリシーを学習する。多様なエージェントの集団と対戦することで頑健性を向上させる。
- アクション選択:観察と候補をLLM埋め込みAPIでベクトル化し、残差自己注意エンコーダを用いて観察と候補の埋め込み間のスケールドドット積に比例する確率を計算する。

実験結果
リサーチクエスチョン
- RQ1純粋なLLMベースエージェントが複雑な言語ゲームをプレイする際の内在的バイアスをどのように克服できるか。
- RQ2LLMの推論と学習済みRLポリシーを組み合わせるとWerewolfにおける戦略的意思決定は改善されるか。
- RQ3多様な言語アクションを生成し人口ベースのトレーニングを行うことで、様々な対戦相手に対してより頑健なポリシーを得られるか。
主な発見
- 提案されたRLフレームワークを用いたエージェントは内在的バイアスを克服し、純粋なLLMベースエージェントよりも均一で戦略的なアクション分布を示す。
- ラウンドロビン方式の対局において、戦略的言語エージェントはVillagersおよびWerewolvesの双方で複数のベースラインに対して最高の勝率を達成する。
- 人間-エージェント実験では、エージェントは人間と同程度の勝率に達し、いくつかの設定では人間のパフォーマンスを超える。
- アブレーション実験は、隠れ役割推定、多様なアクション生成、人口ベースのRLの3要素すべてが性能向上に寄与することを示し、RLポリシーがバイアス克服に不可欠である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。