[論文レビュー] Language-based Action Concept Spaces Improve Video Self-Supervised Learning
この論文は画像 CLIP をビデオに適用するために、言語グラウンドのアクション概念空間と自己蒸留を用いて、アクション認識ベンチマークでゼロショット・リニアプロービング・トランダクティブゼロショットを改善する。
Recent contrastive language image pre-training has led to learning highly transferable and robust image representations. However, adapting these models to video domains with minimal supervision remains an open problem. We explore a simple step in that direction, using language tied self-supervised learning to adapt an image CLIP model to the video domain. A backbone modified for temporal modeling is trained under self-distillation settings with train objectives operating in an action concept space. Feature vectors of various action concepts extracted from a language encoder using relevant textual prompts construct this space. We introduce two train objectives, concept distillation and concept alignment, that retain generality of original representations while enforcing relations between actions and their attributes. Our approach improves zero-shot and linear probing performance on three action recognition benchmarks.
研究の動機と目的
- 言語条件付きアクション概念を活用して、ビデオごとのラベルなしで頑健な表現を学習する動機づけ。
- SSL を導くために、言語表現から派生したカテゴリ概念空間と説明概念空間を提案する。
- CLIP 的な一般性を維持しつつ、アクション属性関係を捉える二つの SSL 目的(概念蒸留と概念整合)を開発する。
- キャプションや各動画ラベルなしで、ビデオで訓練されたモデルからダウンストリームのアクション認識をゼロショットで実現可能にする。
提案手法
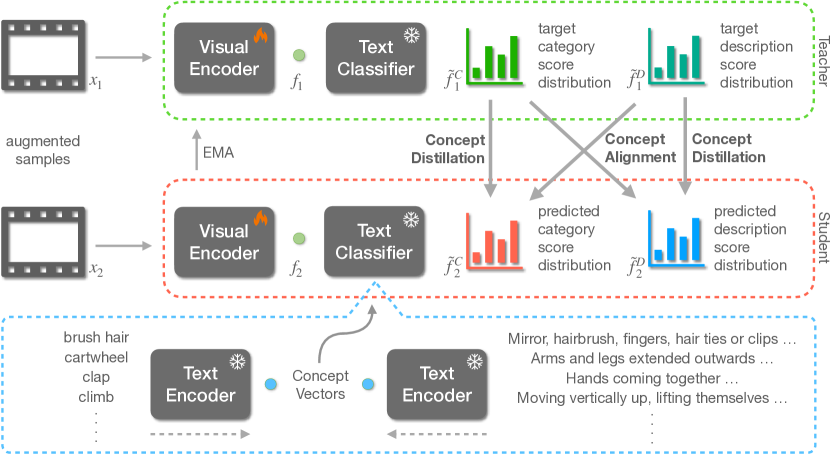
- 時間モデリングのための因子分解空間-時間注意機構を備えた CLIP ベースの視覚バックボーンを使用する。
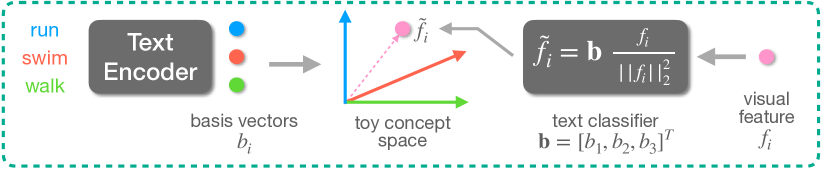
- 視覚特徴をアクション概念空間へ射影するテキスト分類器(CLIP テキストエンコーダの凍結埋め込み)を導入する。
- 言語から二つの概念空間を构成する:カテゴリ概念空間(アクションラベル)と説明概念空間(説明/属性)。
- 各概念空間での二つの拡張ビューを EMA 教師-生徒構成を用いた蒸留損失で一致させ、概念スコアのシャープ化ソフトマックスを適用する。
- 崩壊を防ぐための一様分布事前を追加し、カテゴリ空間と説明空間をビュー間で結ぶ概念整合損失を導入する。
- ラベル生成とスケーラビリティを探るため、カテゴリ概念空間のバリアント(LSS-A、LSS-B、LSS-C)をサポートする。
実験結果
リサーチクエスチョン
- RQ1言語由来のアクション概念は、ビデオ SSL を改善し、CLIP 的表現がビデオタスクへより良く転移するか?
- RQ2言語整列概念空間での概念蒸留と概念整合は、標準ベンチマークでのゼロショットおよびリニアプロービング性能を改善するか?
- RQ3カテゴリ/説明概念空間の構成(LLM によるラベル生成を含む)は、SSL の成果とスケーラビリティにどのような影響を与えるか?
主な発見
- HMDB-51およびUCF-101で、ビデオレベルのラベルやキャプションを使用せずに、従来の SSL 手法と比較して最先端のリニアプロービング結果を達成。
- ゼロショット転移での HMDB-51 および UCF-101 において従来の CLIP 風モデルを上回り、HMDB-51・UCF-101・Kinetics-400 に跨る強力なトランザクティブゼロショット性能を示す。
- 二つの新規 SSL 目的(概念蒸留と概念整合)が、一様分布事前と組み合わせた場合を含め、ベースラインを一貫して改善する。
- 言語整列型アクション概念空間は、画像 CLIP 表現のビデオ領域への転送性を維持・向上させ、ゼロショット機能を実現することを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。