[論文レビュー] Language Instructed Reinforcement Learning for Human-AI Coordination
本論文は instructRL を紹介する。自然言語指示と大規模言語モデルを用いてマルチエージェント強化学習を正規化し、AI パートナーが人間と協調して人間に適合した均衡へ向かうようにする。Say-Select と Hanabi でデモンストレーション。
One of the fundamental quests of AI is to produce agents that coordinate well with humans. This problem is challenging, especially in domains that lack high quality human behavioral data, because multi-agent reinforcement learning (RL) often converges to different equilibria from the ones that humans prefer. We propose a novel framework, instructRL, that enables humans to specify what kind of strategies they expect from their AI partners through natural language instructions. We use pretrained large language models to generate a prior policy conditioned on the human instruction and use the prior to regularize the RL objective. This leads to the RL agent converging to equilibria that are aligned with human preferences. We show that instructRL converges to human-like policies that satisfy the given instructions in a proof-of-concept environment as well as the challenging Hanabi benchmark. Finally, we show that knowing the language instruction significantly boosts human-AI coordination performance in human evaluations in Hanabi.
研究の動機と目的
- 自然言語指示を介して均衡選択を指導することにより、AI パートナーが人間と協調するようにする。
- 人間の指示に条件づけられた事前ポリシーを生成するために、事前学習済み言語モデルを活用する。
- LLM の事前分布を用いて RL 学習を正規化し、人間が好む均衡へ収束させる。
- 設計された Say-Select ゲームと Hanabi ベンチマークでこのアプローチを実証する。
- 指示が知られている場合に、言語情報を活用したエージェントが協調を改善することを人間の評価を通じて示す。
提案手法
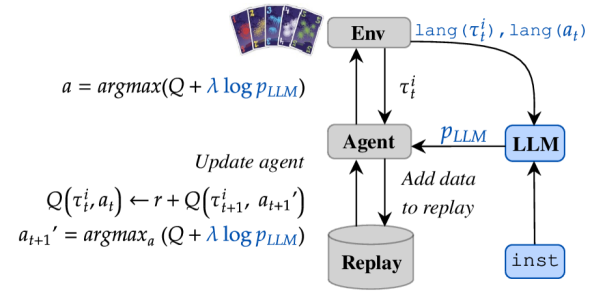
- 人間の指示と現在の観測記述に条件づけられた LLM ベースの事前ポリシーを構築する。
- 行動と観測を言語記述にマッピングして、LLM に妥当な行動を問い合わせる。
- LLM の事前分布を用いて、対数確率の増補または KL ペナルティを介して Q 学習と PPO を正規化する。
- instructRL が言語指示を満たす均衡へ誘導できることを示す。
- 具体的な二つのアルゴリズムの具現化を提供する: instructQ (log pLLM 付き Q 学習) と instructPPO (pLLM への KL を用いる PPO)。
- 並列トレーニングを適用し、正規化ウェイトをアニーリングして RL 中の LLM ガイダンスを統合する。
実験結果
リサーチクエスチョン
- RQ1協調タスクにおいて自然言語指示はマルチエージェント RLを人間が好む均衡へ導くことができるか?
- RQ2政策学習をLLMの事前分布に条件づけることは Say-Select と Hanabi で人間と互換のあるポリシーにつながるか?
- RQ3言語で誘導された正規化で訓練されたエージェントは、標準的な MARL のベースラインと比較して人間とAIの協調を改善するか?
- RQ4得られたポリシーは解釈可能で、異なる環境で与えられた指示と一致しているか?
主な発見
| 手法 | セルフプレイ | 内部-AXP |
|---|---|---|
| Q-learning | 23.96 ± 0.05 | 23.77 ± 0.07 |
| InstructQ (color) | 23.78 ± 0.05 | 23.77 ± 0.06 |
| InstructQ (rank) | 23.92 ± 0.02 | 23.78 ± 0.05 |
| PPO | 24.25 ± 0.01 | 24.25 ± 0.01 |
| InstructPPO (color) | 24.25 ± 0.03 | 24.23 ± 0.01 |
| InstructPPO (rank) | 24.10 ± 0.02 | 24.08 ± 0.02 |
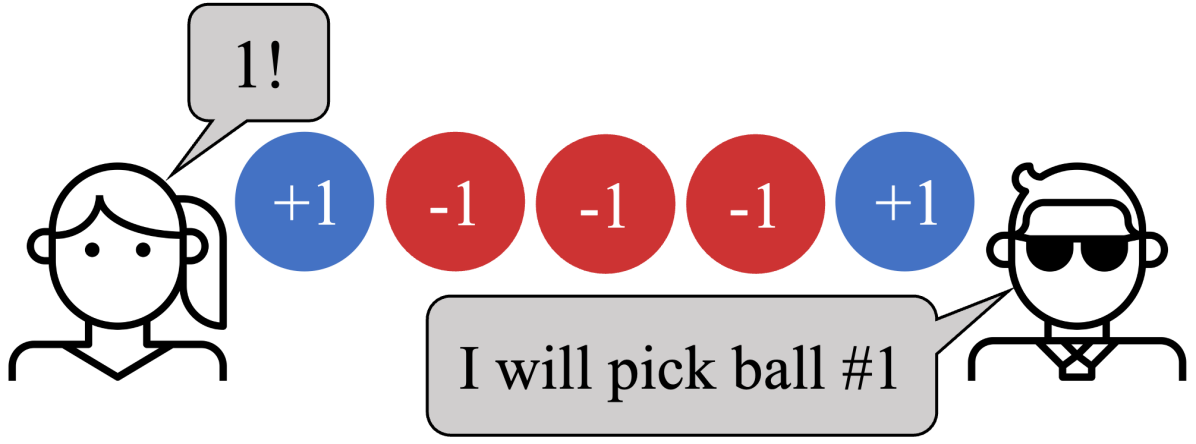
- Say-Select では、instructQ は“ I should select the same number as my partner.”という指示と整合するポリシーを生み出す。
- Hanabi では、instructQ と instructPPO は指示に従って意味的に異なるポリシーを生み出す(色ベース vs ランクベース)。
- instructQ と instructPPO はともに自己対話(self-play)および intra-AXP パフォーマンスをバニラベースラインと同等に達成し、頑健な収束を示している。
- 人間の評価は、指示が人間に知られている場合、言語情報を用いたエージェントと協調することで性能が向上することを示している。
- この手法は、大規模な人間デモンストレーションデータセットを必要とせず、言語ベースのガイダンスをエージェントに与えることで均衡を誘導できることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。