[論文レビュー] Language Modeling Is Compression
本論は予測を不可逆圧縮として再定義し、巨大言語モデルがテキスト・画像・音声を横断するコンテキスト内圧縮に卓越した汎用予測子として機能することを示し、スケーリング、トークナイゼーション、圧縮機を生成モデルとして利用することを分析する。
It has long been established that predictive models can be transformed into lossless compressors and vice versa. Incidentally, in recent years, the machine learning community has focused on training increasingly large and powerful self-supervised (language) models. Since these large language models exhibit impressive predictive capabilities, they are well-positioned to be strong compressors. In this work, we advocate for viewing the prediction problem through the lens of compression and evaluate the compression capabilities of large (foundation) models. We show that large language models are powerful general-purpose predictors and that the compression viewpoint provides novel insights into scaling laws, tokenization, and in-context learning. For example, Chinchilla 70B, while trained primarily on text, compresses ImageNet patches to 43.4% and LibriSpeech samples to 16.4% of their raw size, beating domain-specific compressors like PNG (58.5%) or FLAC (30.3%), respectively. Finally, we show that the prediction-compression equivalence allows us to use any compressor (like gzip) to build a conditional generative model.
研究の動機と目的
- 損失なし圧縮と情報理論の視点から基盤モデルの研究を動機づける。
- モダリティを横断する大規模言語モデルのオフライン(文脈内)圧縮能力を経験的に評価する。
- 圧縮性能に対するスケーリング法則と文脈長・モデルサイズの影響を分析する。
- 圧縮機を条件付き生成モデルとして再利用する方法を示す。
- トークナイゼーションとデータモダリティが圧縮効率に及ぼす役割を検討する。
提案手法
- TransformerおよびChinchilla風モデルからの確率予測を用いた算術符号化を使って、損失のない圧縮機を作成する。
- テキスト(enwik9)、画像(ImageNetパッチ)、および音声(LibriSpeech)からの1 GBサンプルで圧縮を評価する。
- 一般目的の圧縮機(gzip、LZMA2)およびドメイン特化の圧縮機(PNG、FLAC)と比較する。
- 最適な調整圧縮率のためのモデルサイズとデータセットサイズのトレードオフを調査する。
- prior sequence に条件付けした生成モデルとして圧縮機からのサンプル生成方法を実演する。
実験結果
リサーチクエスチョン
- RQ1主にテキストで訓練された基盤モデルは、複数のデータモダリティに跨る汎用圧縮機として機能し得るか。
- RQ2文脈長とモデルサイズは文脈内圧縮性能にどう影響するか。
- RQ3大規模モデルと組み合わせたとき、トークナイゼーション方式は圧縮を改善するか、あるいは損なうか。
- RQ4圧縮機はテキスト、画像、音声データの条件付き生成モデルとして使えるか。
- RQ5データサイズに対する圧縮性能のスケーリング法則の影響は何か。
主な発見
| チャンクサイズ | 圧縮機 | enwik9 Raw (%) | ImageNet Raw (%) | LibriSpeech Raw (%) | Random Raw (%) | enwik9 Adjusted (%) | ImageNet Adjusted (%) | LibriSpeech Adjusted (%) | Random Adjusted (%) |
|---|---|---|---|---|---|---|---|---|---|
| ∞ | gzip | 32.3 | 70.7 | 36.4 | 100.0 | 32.3 | 70.7 | 36.4 | 100.0 |
| ∞ | LZMA2 | 23.0 | 57.9 | 29.9 | 100.0 | 23.0 | 57.9 | 29.9 | 100.0 |
| ∞ | PNG | 42.9 | 58.5 | 32.2 | 100.0 | 42.9 | 58.5 | 32.2 | 100.0 |
| ∞ | FLAC | 89.5 | 61.9 | 30.9 | 107.8 | 89.5 | 61.9 | 30.9 | 107.8 |
| 2048 | gzip | 48.1 | 68.6 | 38.5 | 100.1 | 48.1 | 68.6 | 38.5 | 100.1 |
| 2048 | LZMA2 | 50.0 | 62.4 | 38.2 | 100.0 | 50.0 | 62.4 | 38.2 | 100.0 |
| 2048 | PNG | 80.6 | 61.7 | 37.6 | 103.2 | 80.6 | 61.7 | 37.6 | 103.2 |
| 2048 | FLAC | 88.9 | 60.9 | 30.3 | 107.2 | 88.9 | 60.9 | 30.3 | 107.2 |
| 200K | Transformer | 30.9 | 194.0 | 146.6 | 195.5 | 30.9 | 194.0 | 146.6 | 195.5 |
| 800K | Transformer | 21.9 | 185.3 | 131.3 | 200.3 | 21.9 | 185.3 | 131.3 | 200.3 |
| 3.2M | Transformer | 17.7 | 216.5 | 228.9 | 224.7 | 17.7 | 216.5 | 228.9 | 224.7 |
| 1B | Chinchilla | 211.3 | 262.2 | 224.9 | 308.8 | 1410.2 | 1454.7 | 1423.6 | 1501.6 |
| 7B | Chinchilla | 1410.2 | 1454.7 | 1423.6 | 1501.6 | 1410.2 | 1454.7 | 1423.6 | 1501.6 |
| 70B | Chinchilla | 14008.3 | 14048.0 | 14021.0 | 14100.8 | 14008.3 | 14048.0 | 14021.0 | 14100.8 |
- Chinchilla 70B は ImageNet パッチで 43.4% 圧縮、LibriSpeech で 16.4% を達成し、各々のドメインで PNG および FLAC を上回る。
- 大規模基盤モデルは強力な文脈内学習を提供し、テキスト・画像・音声すべてで競争力のあるオフライン圧縮を可能にする。
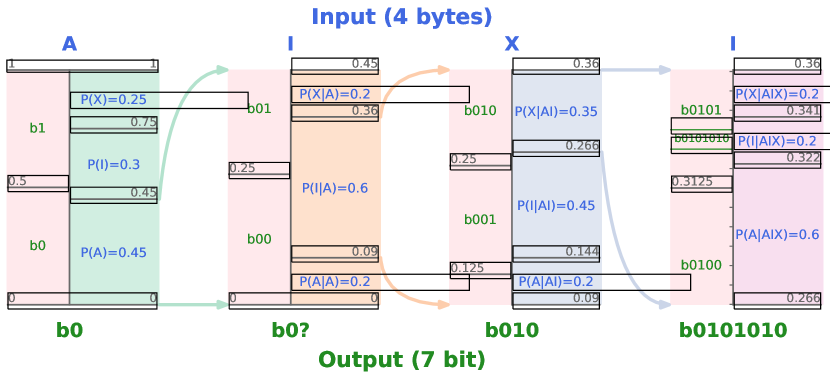
- 圧縮性能はスケーリング傾向に従うが、データセットサイズに制限される。ある閾値を超えると、パラメータ追加はモデルサイズを考慮した調整圧縮率を増加させる。
- トークナイゼーションは小規模モデルでは生の圧縮率を改善しないことが多く、より大きな語彙は大規模モデルの性能を下げる可能性がある。
- prior context に条件付けして条件付き圧縮長の差に従ってサンプリングすることで、生成モデルとして圧縮機を用いることが可能である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。