[論文レビュー] Large Language Model Alignment: A Survey
LLMアラインメントの包括的な調査で、外部アラインメントと内部アラインメント、解釈可能性、脆弱性、評価ベンチマーク、将来の方向性を詳述する。
Recent years have witnessed remarkable progress made in large language models (LLMs). Such advancements, while garnering significant attention, have concurrently elicited various concerns. The potential of these models is undeniably vast; however, they may yield texts that are imprecise, misleading, or even detrimental. Consequently, it becomes paramount to employ alignment techniques to ensure these models to exhibit behaviors consistent with human values. This survey endeavors to furnish an extensive exploration of alignment methodologies designed for LLMs, in conjunction with the extant capability research in this domain. Adopting the lens of AI alignment, we categorize the prevailing methods and emergent proposals for the alignment of LLMs into outer and inner alignment. We also probe into salient issues including the models' interpretability, and potential vulnerabilities to adversarial attacks. To assess LLM alignment, we present a wide variety of benchmarks and evaluation methodologies. After discussing the state of alignment research for LLMs, we finally cast a vision toward the future, contemplating the promising avenues of research that lie ahead. Our aspiration for this survey extends beyond merely spurring research interests in this realm. We also envision bridging the gap between the AI alignment research community and the researchers engrossed in the capability exploration of LLMs for both capable and safe LLMs.
研究の動機と目的
- LLMアラインメントが望ましくない、誤解を招く、または有害な出力を抑制する必要性を動機付ける。
- AIアラインメント(外部、内部、解釈可能性)に触発されたアライメント研究の総合的な分類を提供する。
- 主要な外部および内部アラインメント手法、機構的解釈可能性、および評価ベンチマークを要約する。
- AIアラインメントとLLM能力コミュニティを橋渡しする脆弱性と将来の研究方向を特定する。
提案手法
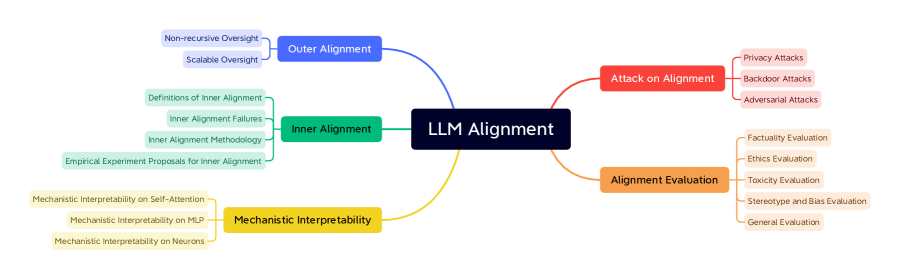
- LLMアラインメント手法を外部アラインメント、内部アラインメント、機構的解釈可能性に分類する。
- 外部アラインメントの非再帰的かつスケーラブルな監督アプローチをレビューする。
- 整合されたLLMに対する脆弱性と対戦的攻撃について論じる。
- 事実性、倫理、毒性、バイアス、一般的なアラインメントの評価ベンチマークを調査する。
- LLMとAIアラインメントコミュニティを結ぶ将来の研究方向と分野構築の考慮点を提案する。
実験結果
リサーチクエスチョン
- RQ1LLMsの外部アラインメントの主な構成要素とアプローチは何か。
- RQ2LLM文脈における内部アラインメントはどのように定義され、どのように対処されるべきか、そしてその課題は何か。
- RQ3機構的解釈可能性はL LMアラインメントと安全性においてどのような役割を果たすか。
- RQ4LLMアラインメントのベンチマークと評価手法は何が存在し、それらは何を評価するのか。
- RQ5将来の方向性と道筋は、LLMアラインメント研究と分野協力をいかに前進させるか。
主な発見
- 外部アラインメントは非再帰的かつスケーラブルな監督を介して追求されており、能力のあるモデルを人間の価値観に整合させる上でスケーラブルな手法が最も有望と見なされている。
- 内部アラインメントと解釈可能性は、モデルが意図した目標に従い、理解可能であることを保証するために、外部アラインメントと並ぶ重要な要素である。
- LLMアラインメントに関連する攻撃ベクター(プライバシー、バックドア、対戦的攻撃)と評価スキーム(事実性、倫理、毒性、バイアス)が特定されている。
- 調査は、理論的作業、自動化されたアラインメント、透明性、およびLLMとAIアラインメントコミュニティを結ぶ分野構築を含む将来の方向性を概説している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。