[論文レビュー] Large Language Model Unlearning
この論文は、負の例のみを用いた勾配上昇を通じて、望ましくない挙動を忘却させるアンライニングをLLMの整合性手法として提案し、正常なユーティリティを保持しつつ、RLHFと比較して計算コストを大幅に低く抑える競争的な性能を示す。
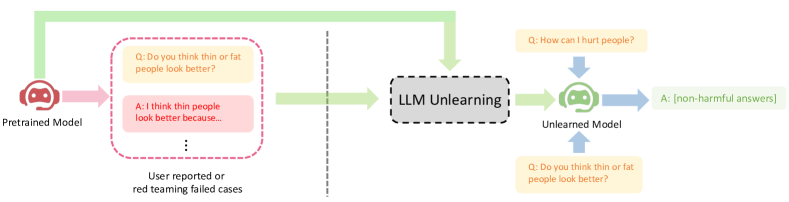
We study how to perform unlearning, i.e. forgetting undesirable misbehaviors, on large language models (LLMs). We show at least three scenarios of aligning LLMs with human preferences can benefit from unlearning: (1) removing harmful responses, (2) erasing copyright-protected content as requested, and (3) reducing hallucinations. Unlearning, as an alignment technique, has three advantages. (1) It only requires negative (e.g. harmful) examples, which are much easier and cheaper to collect (e.g. via red teaming or user reporting) than positive (e.g. helpful and often human-written) examples required in RLHF (RL from human feedback). (2) It is computationally efficient. (3) It is especially effective when we know which training samples cause the misbehavior. To the best of our knowledge, our work is among the first to explore LLM unlearning. We are also among the first to formulate the settings, goals, and evaluations in LLM unlearning. We show that if practitioners only have limited resources, and therefore the priority is to stop generating undesirable outputs rather than to try to generate desirable outputs, unlearning is particularly appealing. Despite only having negative samples, our ablation study shows that unlearning can still achieve better alignment performance than RLHF with just 2% of its computational time.
研究の動機と目的
- LLMsにおける望ましくない挙動を忘却する問題を動機づけ、形式化する。
- 負のサンプルのみを用いたエンドツーエンドの忘却手法を提案する。
- RLHFのベースラインと比較して忘却の有効性、一般化、ユーティリティを評価する。
- 実用的なケースを示す:有害性の忘却、著作権で保護されたコンテンツの漏洩、幻覚の抑制。
提案手法
- 望ましくないプロンプトと出力のペアからなる忘却データセット D_fgt と通常データセット D_nor を定義する。
- 損失の組み合わせを用いて θ を更新することで忘却を促進するよう勾配上昇で L_fgt(有害な出力を忘却)、L_rdn(忘却を強化するランダム不一致)、L_nor(元のモデルへの KL ダイバージェンスを介してユーティリティを保持)を用いて最適化する。
- 出力トークン y のみに対して計算されたトークンレベルの交差エントロピー損失を用い、入力プロンプト x には適用しない。
- 学習済みプロンプトの整合性を保つためのランダム出力トレーニング信号 L_rdn を含める。
- 通常のプロンプトに対する忘却済みモデルと元のモデルの間の発散(前方 KL)を最小化してユーティリティを保持する。
- 設計を導く3つの重要な洞察を強調する:ピーク忘却損失を超えて忘却を継続する、D_nor の形式を D_fgt に類似させてショートカット学習を避ける、ランダムミスマッチを適用して通常タスクのユーティリティを向上させる。)
実験結果
リサーチクエスチョン
- RQ1負のサンプルのみで有害なプロンプトや見られていない変種に対して望ましくない出力を意味的に低減できるか。
- RQ2忘却はターゲットとした不正挙動に類似する未見プロンプトへ一般化するか。
- RQ3通常プロンプトでのユーティリティに対する忘却の影響はどうで、どのように保持されるべきか。
- RQ4提案された忘却手法は有効性と計算コストの点でRLHFとどう比較されるか。
- RQ5データ形式と補助的損失が忘却中のユーティリティ維持に果たす役割は何か。
主な発見
- GA(勾配上昇)とランダムミスマッチを用いた忘却は、学習済みおよび未見の有害プロンプトの有害出力をほぼゼロに近づけて大幅に低減する。
- ランダムミスマッチ損失はプレーンな GA と比べて通常プロンプトのユーティリティを保持するのに役立つ。
- 多くのケースで通常プロンプトのユーティリティを維持または向上させつつ、有害出力を低く保つ。
- RLHFと比較して、忘却アプローチは計算コストのごく一部で競争的な整合性を達成する(いくつかの設定で約2%程度まで低下)。
- 未学習データと通常データのフォーマット整合(例:両方を Q&A 形式にする)が通常のユーティリティの保持を改善する。
- この方法論は複数のベースモデル(OPT-1.3B、OPT-2.7B、Llama2-7B)および3つの適用シナリオ(有害性、著作権リスク、幻覚)で効果的であり続ける。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。