[論文レビュー] Large Language Models are Capable of Offering Cognitive Reappraisal, if Guided
RESORTの規範に導かれたLLMsは、感情的サポートのための標的化された認知再評価を生成でき、専門の心理学者がベースラインに対する改善を評価し、オープンソースモデルがGPT-4 turboの性能に近づく。一方、GPT-4は再評価を評価する際、専門家の評価に対して中程度に同意できる。
Large language models (LLMs) have offered new opportunities for emotional support, and recent work has shown that they can produce empathic responses to people in distress. However, long-term mental well-being requires emotional self-regulation, where a one-time empathic response falls short. This work takes a first step by engaging with cognitive reappraisals, a strategy from psychology practitioners that uses language to targetedly change negative appraisals that an individual makes of the situation; such appraisals is known to sit at the root of human emotional experience. We hypothesize that psychologically grounded principles could enable such advanced psychology capabilities in LLMs, and design RESORT which consists of a series of reappraisal constitutions across multiple dimensions that can be used as LLM instructions. We conduct a first-of-its-kind expert evaluation (by clinical psychologists with M.S. or Ph.D. degrees) of an LLM's zero-shot ability to generate cognitive reappraisal responses to medium-length social media messages asking for support. This fine-grained evaluation showed that even LLMs at the 7B scale guided by RESORT are capable of generating empathic responses that can help users reappraise their situations.
研究の動機と目的
- 長期的な情動的ウェルビーイングのための認知評価ベースの介入の活用を促す。
- 心理学的に根拠のある六つの評価次元からなる枠組みRESORTを、LLMの指示として提案する。
- 専門家心理学者を通じてRESORT指導のもとでLLMsがゼロショットで標的化された再評価を生成できるかを評価する。
- 再評価の生成においてオープンソースLLMとGPT-4 turboを比較し、安全性、事実性、共感を評価する。
提案手法
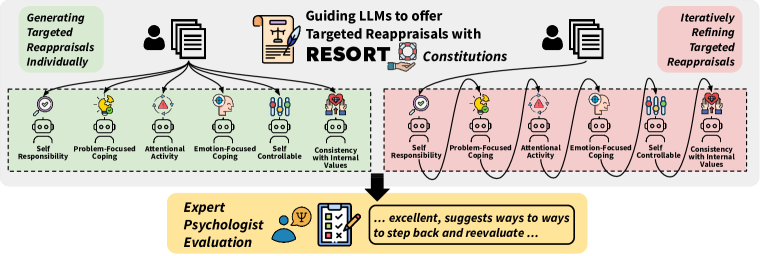
- 再評価生成を導く規範を備えた六つの評価次元であるRESORTを導入する。
- 個別指導型の再評価と反復的なガイド付き改良という二つのプロンプト戦略を定式化する。
- 再評価を生成する前に明示的な評価識別を追加することもできる。
- 整合性、共感、有害性、および事実性の基準を用いて専門の心理学者とともに出力を評価する。
実験結果
リサーチクエスチョン
- RQ1LLMsはゼロショット設定で、心理学的に根拠のある規範(RESORT)に整合した標的化された認知再評価を生成できるか?
- RQ2明示的な評価識別および/または反復的改良は再評価の整合性と共感を改善するか?
- RQ3オープンソースLLMとRESORTは、再評価の生成においてGPT-4 turboと同等の性能を達成するか?
- RQ4人間著者の参照と比較した場合、LLM生成の再評価の信頼性と安全性(有害性および事実性)はどうか?
主な発見
- RESORTに導かれたLLMsは、ベースラインと比較して規範との整合性を大幅に改善する。
- 明示的な評価識別と反復的改良は、さらに整合性と共感スコアを高める。
- オープンソースモデル(LLaMA-2 13B-chat、Mistral 7B-instruct)は、再評価タスクでGPT-4 turboと同等の性能を達成する。
- GPT-4は再評価を評価する際に専門家評価者と中程度に同意でき、プロトタイピングの自動評価者としての利用を支持する。
- 研究の約98%のLLM生成の再評価は有害ではないと評価され、多くのケースでトップRedditコメントより事実性が高かった。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。