[論文レビュー] Large Language Models are Edge-Case Fuzzers: Testing Deep Learning Libraries via FuzzGPT
FuzzGPT は LLM を促して珍しい、端数の Python コードスニペットを生成させ、DL ライブラリを fuzz し、過去のバグデータをインコンテキスト学習とファインチューニングを通じて活用することで TitanFuzz を上回る。
Deep Learning (DL) library bugs affect downstream DL applications, emphasizing the need for reliable systems. Generating valid input programs for fuzzing DL libraries is challenging due to the need for satisfying both language syntax/semantics and constraints for constructing valid computational graphs. Recently, the TitanFuzz work demonstrates that modern Large Language Models (LLMs) can be directly leveraged to implicitly learn all the constraints to generate valid DL programs for fuzzing. However, LLMs tend to generate ordinary programs following similar patterns seen in their massive training corpora, while fuzzing favors unusual inputs that cover edge cases or are unlikely to be manually produced. To fill this gap, this paper proposes FuzzGPT, the first technique to prime LLMs to synthesize unusual programs for fuzzing. FuzzGPT is built on the well-known hypothesis that historical bug-triggering programs may include rare/valuable code ingredients important for bug finding. Traditional techniques leveraging such historical information require intensive human efforts to design dedicated generators and ensure the validity of generated programs. FuzzGPT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (including fine-tuning and in-context learning), while being generalizable and applicable to challenging domains. While FuzzGPT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: Codex and CodeGen. Moreover, FuzzGPT also shows the potential of directly leveraging the instruct-following capability of the recent ChatGPT for effective fuzzing. Evaluation on two popular DL libraries (PyTorch and TensorFlow) shows that FuzzGPT can substantially outperform TitanFuzz, detecting 76 bugs, with 49 already confirmed as previously unknown bugs, including 11 high-priority bugs or security vulnerabilities.
研究の動機と目的
- DL ライブラリのバグが及ぼす広範な影響を考慮して、堅牢なテストを促進する。
- LLMs を活用して過去のバグを引き起こすコードを利用して珍しい入力プログラムを生成する FuzzGPT を提案する。
- インコンテキスト学習とファインチューニングを通じてバグを引き起こすコード生成を自動化する。
- PyTorch と TensorFlow で FuzzGPT を評価し、TitanFuzz と比較する。
- 自動 fuzzing による新たなバグと潜在的な脆弱性の発見を実証する。
提案手法
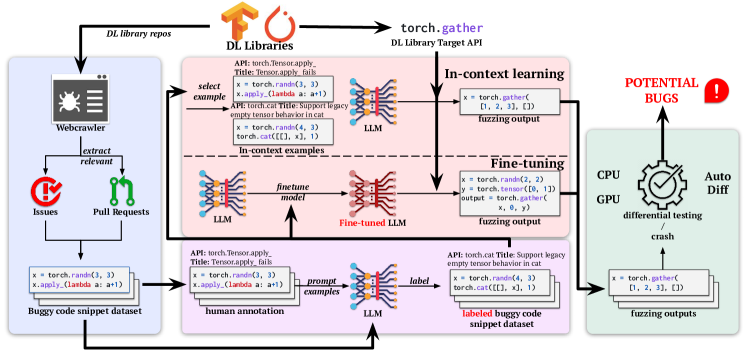
- ターゲット DL ライブラリの GitHub issue や PR から過去のバグを引き起こすコード断片を収集する。
- 自己訓練型 LLM アプローチを用いて、 few manual labels を使い各コード断片の buggy API を注釈付けする。
- 端境界ケースの fuzzing コードを生成するための三つの学習戦略を適用する: few-shot in-context learning、zero-shot completion/editing、バグを引き起こすコードでのファインチューニング。
- 生成されたプログラムをクラッシュ、CPU/GPU 一貫性、および自動微分 (AD) オラクルで実行してバグを検出する。
- Codex と CodeGen LLM、および PyTorch と TensorFlow ライブラリ上で zero-shot ChatGPT バリアントを用いて評価する。

実験結果
リサーチクエスチョン
- RQ1RQ1: FuzzGPT の異なる学習パラダイム(few-shot、zero-shot、ファインチューニング)は効果においてどのように比較されるか。
- RQ2RQ2: FuzzGPT は TitanFuzz のような既存のファザーとどう比較されるか。
- RQ3RQ3: FuzzGPT の主要なコンポーネントはその有効性にどのように寄与するか。
- RQ4RQ4: 実世界の DL ライブラリで新しいバグを検出できるか。
主な発見
- FuzzGPT のバリアントは PyTorch/TensorFlow でのカバレッジを TitanFuzz よりそれぞれ 60.70%/36.03% 高める。
- FuzzGPT は最新の PyTorch および TensorFlow バージョンで合計 76 のバグを発見した。
- このうち 49 種類が新たに特定され、うち 11 種類は高優先度またはセキュリティ関連と分類される。
- 本研究は GitHub から 1,750 件の PyTorch バグトリガー断片と 633 件の TensorFlow を使用した。
- FuzzGPT は Codex、CodeGen、ChatGPT ベースの zero-shot バリアントで有効性を示す。
- このアプローチは完全自動化されており、DL ライブラリ以外の他ドメインにも一般化可能である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。