[論文レビュー] Large Language Models are Inconsistent and Biased Evaluators
この論文は、LLM評価者がサンプルやプロンプトごとに偏りがあり一貫性がないことを示し、緩和レシピを提案し、RoSEでの改善を実証している。
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low "inter-sample" agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
研究の動機と目的
- 要約タスクにおけるLLMベース評価者の偏りと一貫性を評価する。
- SummEvalとRoSEデータセットを用いて熟知バイアス、採点の偏り、アンカリング効果を定量化する。
- 特定された課題を緩和する実用レシピを開発・検証する。
- RoSE CNNDMおよびSAMSumパーティションで、強化されたLLM評価者を最先端ベースラインと比較する。
提案手法
- 複数のプロンプトと生成設定を用いてSummEvalとRoSE上でLLM評価者(GPT-3.5およびGPT-4)を分析する。
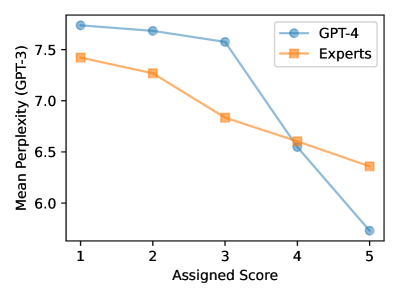
- 評価とパープレキシティの相関を用いて熟知度を測定する。
- 1-5, 1-10, 1-100のスケールでの評価粒度を試し、複数サンプルで平均化して調べる。
- 一つの生成で複数属性を予測することでアンカリングを調べ、属性の並べ替えを行う。
- Krippendorffのαを用いてサンプル間の一貫性とアノテーター間の一致度を評価し、Kendallのτで人間判断と比較する。
- 緩和戦略のレシピを提案し、RoSEで検証し、G-EvalおよびChiang & Lee (2023)と比較する。
- RoSE CNNDMとSAMSumパーティションで性能向上を示すケーススタディを実施する。
実験結果
リサーチクエスチョン
- RQ1LLM評価者は要約評価において熟知度バイアス、採点の偏り、アンカリング効果を示すか。
- RQ2人間の評価者と比較して、サンプルやプロンプトの変化に対してLLM評価者は一貫性があるか。
- RQ3具体的な緩和レシピのセットは、LLM評価者の信頼性と整合性を改善できるか。
- RQ4提案手法は、最先端ベースラインと比較してRoSEで統計的に有意な改善をもたらすか。
主な発見
- LLM評価者は熟知度バイアスを示し、低パープレキシティの要約を人間の専門家と比較して好む。
- LLMsは1次の丸数字の嗜好や粒度のばらつきといった採点の偏りを示す。
- 複数属性を1つの出力で予測するとアンカリング効果が生じ、以降のスコアに影響を与える。
- LLM評価者のサンプル間合意は人間のアノテーター間合意より低く、自己不一致を示す。
- ソース文書を除外すると評価者の性能が大幅に低下し、ソース特徴への過度の依存を示唆する。
- 0温度の非-CoTプロンプトを用いて1-10スコアを組み合わせたレシピは、RoSE CNNDMとSAMSumパーティションでベースラインを上回り、Kendallのτが約0.22(イン-domain)、0.308(SAMSum)となる。
- RoSEのケーススタディは、提案手法がCNNDMとSAMSumでG-EvalおよびChiang & Lee (2023)より統計的有意に優れていることを示している(ブートストラップ検定)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。