[論文レビュー] Large Language Models Are Semi-Parametric Reinforcement Learning Agents
この論文は Rememberer を紹介する。Rememberer は進化可能な LLM ベースのエージェントで、強化学習によって更新される持続的な外部経験メモリを持ち、LLM のファインチューニングなしに半パラメトリックな RL を可能にする。WebShop と WikiHow のベンチマークで最先端の結果を達成している。
Inspired by the insights in cognitive science with respect to human memory and reasoning mechanism, a novel evolvable LLM-based (Large Language Model) agent framework is proposed as REMEMBERER. By equipping the LLM with a long-term experience memory, REMEMBERER is capable of exploiting the experiences from the past episodes even for different task goals, which excels an LLM-based agent with fixed exemplars or equipped with a transient working memory. We further introduce Reinforcement Learning with Experience Memory (RLEM) to update the memory. Thus, the whole system can learn from the experiences of both success and failure, and evolve its capability without fine-tuning the parameters of the LLM. In this way, the proposed REMEMBERER constitutes a semi-parametric RL agent. Extensive experiments are conducted on two RL task sets to evaluate the proposed framework. The average results with different initialization and training sets exceed the prior SOTA by 4% and 2% for the success rate on two task sets and demonstrate the superiority and robustness of REMEMBERER.
研究の動機と目的
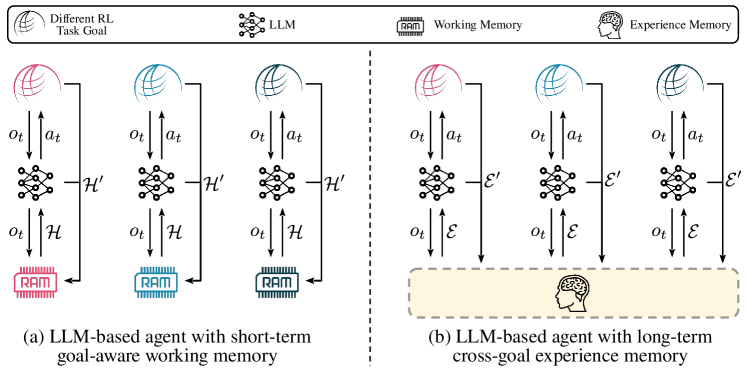
- 長期的な経験メモリを用いて、固定された例示を超えて過去のエピソードから学ぶことができるように、LLMベースのエージェントを動機づける。
- LLMパラメータではなく外部メモリを更新する Reinforcement Learning with Experience Memory (RLEM) を提案する。
- Rememberer を設計して経験を選択的に取得し、インコンテキスト学習のための動的な例示を提供する。
- ベンチマーク RL タスクセット WebShop と WikiHow で頑健性と性能向上を示す。
提案手法
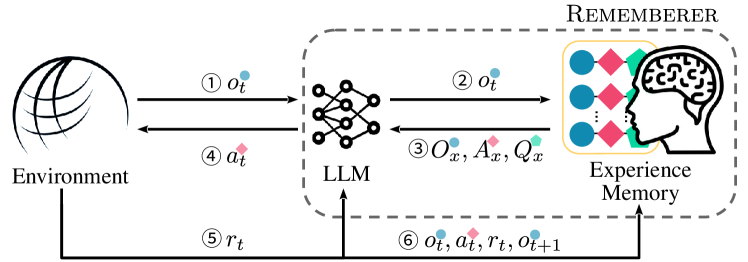
- LLM エージェントのための外部で持続的な経験メモリを導入し、それと環境との相互作用を定義する。
- メモリ内の Q 値更新をベルマン風のルールと、安定性のための任意の n ステップブーストラッピングで定義する。
- メモリからの類似性ベースの検索を用いて、Few-shot プロンプトを導く例示を形成する。
- 思い出した経験を活用するために、奨励アクションと抑制アクションの両方を含む action-advice プロンプト形式を提示する。
- 外部ポリシー外の学習によってメモリを更新し、LLM パラメータをファインチューニングしない。
- WebShop と WikiHow で Rememberer を評価し、最先端のベースラインと比較する。
実験結果
リサーチクエスチョン
- RQ1LLM ベースのエージェントは、モデルパラメータをファインチューニングせずに長期経験メモリから学ぶことができるか?
- RQ2外部メモリを持つ半パラメトリックRLフレームワークは、固定された例示や純粋なRL/IL ベースラインと比べて逐次的意思決定タスクのパフォーマンスを向上させるか?
- RQ3経験をどのように取得し、どのようにLLMに提示すれば、タスク全体で意思決定の質を最大化できるか?
- RQ4ブーストラッピングと抑制アクションを含むメモリ-例示プロンプトの影響はどうか?
- RQ5Rememberer は異なる初期の例示やトレーニングセットに対してどれくらい頑健か?
主な発見
- Rememberer は WebShop で以前の SOTA を上回り、Avg Score 0.68, そして Success Rate 0.39。対して ReAct 0.66 / 0.36、LLM-only 0.55 / 0.29。
- WikiHow では Rememberer は Avg Reward 2.63、Success Rate 0.93 で、LLM-only 2.58/0.90 および Mobile-Env 2.50/0.89 を上回る。
- Rememberer は従来の RL/IL アプローチより、強力な性能を達成するにははるかに少ない注釈付きサンプル(例: 10 タスクで 74 ステップ)で済む。
- アブレーションは、ブーストラッピングが報酬推定の精度と最終性能を改善する一方、観測類似性の欠如はタスク類似性の欠如を除去するより結果を劣化させる。
- 抑制アクションの含有と二成分の類似性(タスクと観測)は性能に大きく影響し、観測類似性は特に重要である。
- 実験は Rememberer が異なる初期の例示とトレーニングセットに対して頑健であることを示し、固定の例示より設定全体で改善を維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。