[論文レビュー] Large Language Models as General Pattern Machines
事前学習済みの LLM は PCFG および ARC の prompts から複雑なトークン列を自己回帰的に完結させ、文脈内学習によるゼロショットのパターン操作を示し、軌道外挿や基本的な閉ループ制御を含む単純なロボティクス課題で実証されている。
We observe that pre-trained large language models (LLMs) are capable of autoregressively completing complex token sequences -- from arbitrary ones procedurally generated by probabilistic context-free grammars (PCFG), to more rich spatial patterns found in the Abstraction and Reasoning Corpus (ARC), a general AI benchmark, prompted in the style of ASCII art. Surprisingly, pattern completion proficiency can be partially retained even when the sequences are expressed using tokens randomly sampled from the vocabulary. These results suggest that without any additional training, LLMs can serve as general sequence modelers, driven by in-context learning. In this work, we investigate how these zero-shot capabilities may be applied to problems in robotics -- from extrapolating sequences of numbers that represent states over time to complete simple motions, to least-to-most prompting of reward-conditioned trajectories that can discover and represent closed-loop policies (e.g., a stabilizing controller for CartPole). While difficult to deploy today for real systems due to latency, context size limitations, and compute costs, the approach of using LLMs to drive low-level control may provide an exciting glimpse into how the patterns among words could be transferred to actions.
研究の動機と目的
- 言語タスクを超える一般的なパターン操作子として LLM の研究を動機づける。
- 非言語的シーケンス(ARC、PCFG)に対するゼロショットのパターン学習能力を評価する。
- シーケンス外挿や基本的なコントローラを含むロボティクスでのこれらの能力のデモンストレーションを探る。
- ファインチューニングなしで低レベルのロボット意思決定を導く際の LLM の制限と潜在的役割を特徴づける。
提案手法
- 入力/出力のシーケンス例をエンコードしたプロンプトを用いた文脈内学習を活用する(ARC に対しては ASCII アート風)。
- パターンのトークン不変性を検証するため、トークン化されたグリッドとランダムなアルファベットで ARC の性能を評価する。
- ARC に依存しないスケーラブルなベンチマークを作成するため、PCFG ベースの構成可能なパターン変換を導入する。
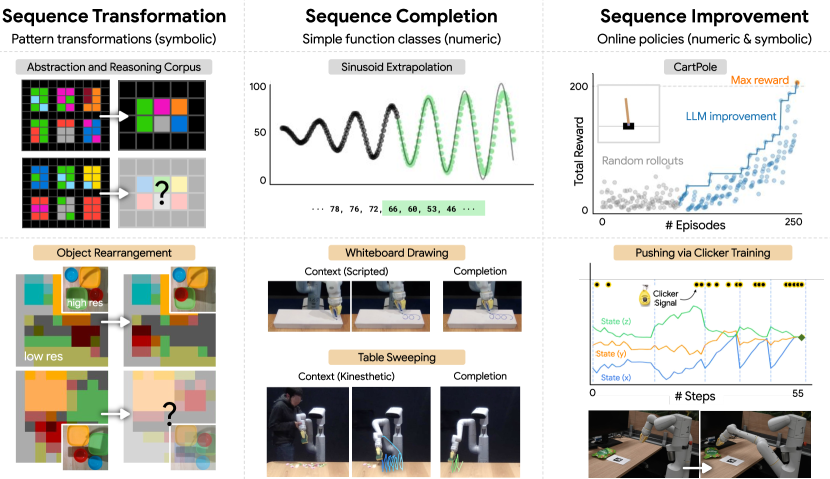
- 運動感覚のデモンストレーションやシンプルなロボット軌道を含む、タスク間でのシーケンス変換、完了、改善を実演する。
- オンライン・報酬条件付き軌道と人間がループするプロンプティングを実験して、シンプルなコントローラ(例:CartPole)を発見する。
- LLM主体の制御を実運用する際の現実的な考慮事項と制約(待ち時間、コンテキストサイズ、計算コスト)を論じる。
![Fig. 1: LLMs out-of-the-box can complete ( highlighted ) complex ARC patterns [ 20 ] expressed in arbitrary tokens.](https://ar5iv.labs.arxiv.org/html/2307.04721/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1事前学習済み LLM はゼロショット設定で非言語トークン上の抽象的なシーケンス変換を実行できるか。
- RQ2トークンの不変性を保ちながらランダムなアルファベットで表現されたパターンで LLM は堅牢なパターン完成を示すか。
- RQ3文脈内 prompting は軌道外挿や基本的な閉ループコントローラの発見といった単純なロボット課題へ拡張できるか。
- RQ4シーケンスベースの制御と方針改善に LLM を用いる際の現実的な制約とトレードオフは何か。
- RQ5PCFG ベースと ARC ベンチマークは、ロボティクスに関連する一般的なパターン能力をどのように明らかにするか。
主な発見
- ASCII アート風にプロンプトした LLM は最大で 85 問題の ARC 問題を解く(800 問中)、訓練なしの一部の DSL ベース手法を上回る。
- トークンマッピングの不変性:ランダムなアルファベットを用いた場合、LLMs は ARC スタイルのタスクの相当部分を解くことができる(例えば、ランダムなアルファベットを用いた設定の 58±1)。
- PCFG ベースのパターン完成はモデル規模とともに改善を示し、より大きなモデルは PCFG のバリアント全般で高い精度を達成する(例:PaLM および text-davinci-003 が小型モデルを上回る)。
- シーケンス完成実験は、より多くの文脈と大規模モデルで正弦関数や関連関数の外挿がほぼ完璧に近づくことを示す。
- シーケンス改善実験は、LLMs が軌道を外挿してより高い報酬を得ること、単純な CartPole コントローラの学習やオンラインの人間主導の軌道最適化を含む、改善を実現できることを示す。
- 適用例として、キネスティックデモンストレーションの外挿(動作)、ホワイトボード上の単純な運動パターン、ロボティクスにおける報酬駆動の軌道改善が挙げられる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。