[論文レビュー] Large Language Models as Optimizers
本論文は Optimization by PROMPTing (OPRO) を提案し、LLMs を最適化子として用いてプロンプト駆動ループ内で新しい解を生成・評価する。さらに、GSM8K および BBH を対象に LLMs によるプロンプト最適化を実演し、LLMs が最適化したプロンプトは一部のタスクで人間設計のプロンプトを上回ることを示す。
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step. We first showcase OPRO on linear regression and traveling salesman problems, then move on to our main application in prompt optimization, where the goal is to find instructions that maximize the task accuracy. With a variety of LLMs, we demonstrate that the best prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks. Code at https://github.com/google-deepmind/opro.
研究の動機と目的
- 過去の解とそれらのスコアに基づいて生成を反復することにより、LLMs が最適化子として機能する方法を説明する。
- 能力と限界を示すために、連続的な問題(線形回帰)と離散的な問題(TSP)に関するケーススタディを紹介する。
- LLMs が NLP ベンチマークでタスク精度を最大化するようにプロンプトを最適化するプロンプト最適化を実証する。
- 一般性と転移性を評価するために、GSM8K と BBH にわたって複数の LLM を最適化子およびスコアラーとして評価する。
提案手法
- メタプロンプトが与えられた場合、LLM が過去の解とスコアの履歴に基づいて新しい候補解を生成する、OPRO(Optimization by PROMPTing)を定義する。
- 各ステップで新しい解を評価し、そのスコアをメタプロンプト内の最適化軌跡に追加する。
- 探索-利用のバランスを取り入れるため、サンプリング温度を調整し、各ステップで複数の候補解を生成する。
- 最適化問題の説明、最適化軌跡、模範問題を含むメタプロンプトを使用して最適化子を導く。
- OPRO を数理タスク(線形回帰と TSP)に適用し、ブラックボックス最適化機能を示す。
- スコアラー LLM を用いて生成されたプロンプトを評価し、最適化子 LLM が新しいプロンプトを生成することで、プロンプト最適化を OPRO に適用し、目的を導く小規模な訓練サブセットを用いる。
- GSM8K および BBH に対して、複数の LLM を最適化子(text-bison、PaLM 2-L、PaLM 2-L-IT、gpt-3.5-turbo、gpt-4)およびスコアラーとして比較する。
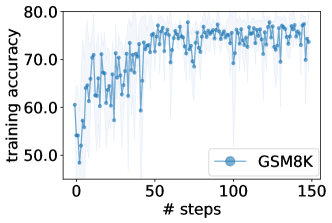
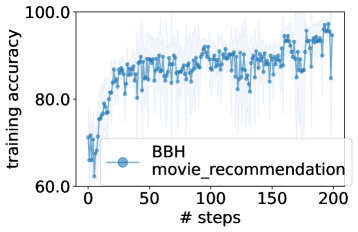
実験結果
リサーチクエスチョン
- RQ1純粋なプロンプトベースのインタラクションのみで、連続問題と離散問題の両方に対して LLMs が有効な最適化子となり得るか?
- RQ2GSM8K や BBH のような NLP ベンチマークで、タスク精度を最大化するためにどれだけうまくプロンプトを最適化できるか?
- RQ3特に大規模な問題に対して、LLMs を最適化子として使用する際の制限と安定性の考慮事項は何か?
- RQ4異なる最適化子およびスコアラー LLM の組み合わせが、プロンプト最適化の性能と転移性にどのように影響するか?
- RQ5最適化されたプロンプトは、関連するベンチマーク間でどの程度転移するか(例:GSM8K から MultiArith や AQuA へ)?
主な発見
- OPRO は LLMs が新しい解を生成し、タスクを横断して最適化軌跡を改善することを可能にする。
- LLMs によって最適化された最高のプロンプトは、GSM8K でゼロショットの人間設計プロンプトを最大8%、Big-Bench Hard のタスクで最大50%超えることがある。
- GPT-4、text-bison、PaLM 2-L-IT、PaLM 2-L は、それぞれ異なるスタイルと強みを示し、より速い収束やより良い最適解を達成するものがある。
- TSP では、GPT-4 が小規模問題で他の LLM を大幅に上回る一方、規模が大きくなると性能が低下し、最適性ギャップで伝統的なヒューリスティクスが LLM を上回る場合がある。
- プロンプト最適化は、最適化を導くのに小さな訓練サブセットで十分であること、そして最適化されたプロンプトが関連する数学データセットに転移することを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。