[論文レビュー] Large Language Models Can Be Easily Distracted by Irrelevant Context
この論文は GSM-IC を導入し、算術推論のための分散性ベンチマークを提示し、関係のない文脈が prompting 手法を著しく害することを示す。自己-consistency と instructed prompting はこの問題を緩和できるが、排除するには至らない。
Large language models have achieved impressive performance on various natural language processing tasks. However, so far they have been evaluated primarily on benchmarks where all information in the input context is relevant for solving the task. In this work, we investigate the distractibility of large language models, i.e., how the model problem-solving accuracy can be influenced by irrelevant context. In particular, we introduce Grade-School Math with Irrelevant Context (GSM-IC), an arithmetic reasoning dataset with irrelevant information in the problem description. We use this benchmark to measure the distractibility of cutting-edge prompting techniques for large language models, and find that the model performance is dramatically decreased when irrelevant information is included. We also identify several approaches for mitigating this deficiency, such as decoding with self-consistency and adding to the prompt an instruction that tells the language model to ignore the irrelevant information.
研究の動機と目的
- 現実的で distractible な入力文脈の下で、すべての情報が関連するとは限らないことを前提に、LLM の評価を動機づける。
- GSM8K derived データセットに、関連性の低い文を挿入してモデルの感度を測定する GSM-IC を構築する。
- GSM-IC に対する最先端の prompting 技術を評価し、モデル間の distractibility を定量化する。
- 関連性の低い文脈に対する頑健性を改善する緩和戦略を特定する(例:self-consistency、 distractor exemplars、 ignore-context instructions)。
提案手法
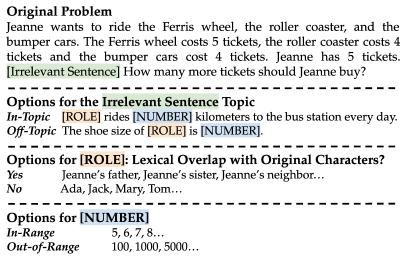
- 基になる GSM8K の問題に正解解を変更せずに関連性の低い文を追加して GSM-IC を作成する。
- GSM-IC で self-consistency の有無を問わず、コード‑davinci‑002 と text‑davinci‑003 を用いて prompting 技術(CoT、0-CoT、LtM、Program)を評価する。
- distractor を含む exemplars や ignore-context instructions を含むプロンプト設計を分析する。
- distractibility と頑健性を定量化するために micro、macro、normalized accuracies を測定する。
- 関連性の低い文脈の要因(話題の重複、役割名の重複、数値の範囲)を分解分析し、その影響を特定する。
- DROP への評価を football の例で拡張し、長文脈に対する頑健性をテストする。
実験結果
リサーチクエスチョン
- RQ1関連性のない文脈情報の含有が、算術推論タスクにおける現在の prompting 技術の正確性にどのように影響するか?
- RQ2self-consistency、 distractor を含む exemplars、 ignore-context instructions などの prompting 戦略は、関連情報に起因する分散性を緩和できるか?
- RQ3関連性の低い文脈のどの要因がモデルの性能に最も影響を与えるか、モデルの構造や prompting スタイルはこの感度をどのように変えるか?
- RQ4GSM-IC での頑健性の改善は他のデータセット/タスク(例:DROP)や異なるモデルファミリーに転用できるか?
主な発見
- 検討されたすべての prompting 技術は関連情報に敏感であり、macro accuracy は有意に低下する(解決済みの割合は一貫して 30% 未満)。
- Self-consistency は頑健性を大幅に高める。問題ごとに 20 サンプルずつの場合、いくつかのプロンプトで正解が最初の回答として 99.7% のサンプルに現れる。
- Exemplar distractors と ignore-context instructions は、プロンプトやモデルを問わず一貫して頑健性を高める。
- LtM は micro accuracy に対しては一般的に最も関連情報に対して頑健だが、macro の改善はモデルや prompting 設定により異なる。
- Breakdown 分析では、話題の重複と同題材の distractors が macro accuracy を最も害することが分かり、数値だけは原問題との語彙的重複より影響が小さい。
- 指示付き prompting(例えば「関連情報を無視するよう指示する」)は顕著な向上をもたらし、指示の種類が重要である(明示的な ignore-context 指示が決定的)。
- DROP においても、LtM およびその指示付き変種は改善をもたらし、GSM-IC を超えたより広い適用性を示唆する。
![Figure 2: Prompt formats for the investigated techniques on the right, which are constructed from building blocks on the left (best viewed in color). The [Problem with Irrelevant Context] is obtained by adding an irrelevant sentence ( italic and underlined ) to the original problem description and i](https://ar5iv.labs.arxiv.org/html/2302.00093/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。