[論文レビュー] Large Language Models for Compiler Optimization
7BパラメータのLLMをゼロから訓練してLLVMアセンブリを最適化することを学習したところ、コードサイズを最小化するためのコンパイラパスを選択し、推論時にコンパイラを実行せずにコンパイラのベースラインより命令数を3.0%削減し、強力なコード推論を示す(91%がコンパイル可能、70%がコンパイラ出力への完全一致)
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
研究の動機と目的
- コード生成と翻訳を超えたコード最適化のためのLLMの探索を促す。
- LLMがコンパイラパスを選択して適用し、コードサイズを最小化することを学べるかを調査する。
- 最適化性能と理解を向上させる補助的な学習タスクを実証する。
- 多様な未知のIRベンチマークに対する堅牢性を評価する。
提案手法
- 複数のLLVM-IRの例と最適なコンパイラオプションおよび結果の最適化IRをペアにしたミリオン規模のデータで、ゼロから7Bパラメータのトランスフォーマー(Llama 2 base)を訓練する。
- 入力: 未最適化 LLVM-IR;出力: opt を介して適用する最適化パスのシーケンス(パスリスト)、122 パスとメタフラグを考慮して扱う。
- 補助的な学習タスク: 最適化前後の命令数を予測し、最適化済みIRを生成して、安全性と理解を深める。
- トークン化と学習のために入力長を削減し、フォーマットを標準化するために LLVM-IR を正規化する。
- オートチューニングを用いて関数ごとのゴールドスタンダードのパスリストを取得し、それを監督信号としてトレーニングセット全体にブロードキャストする。
- 1,000,000 の IR 関数(訓練分割)を用いて約373Mトークンを訓練し、評価指標としてコードサイズの最適化を目指す。
- AI-SOCO、ExeBench、POJ-104、Transcoder、CSmith、YARPGen などの複数ベンチマークで unseen IR 関数100k に対して評価する。
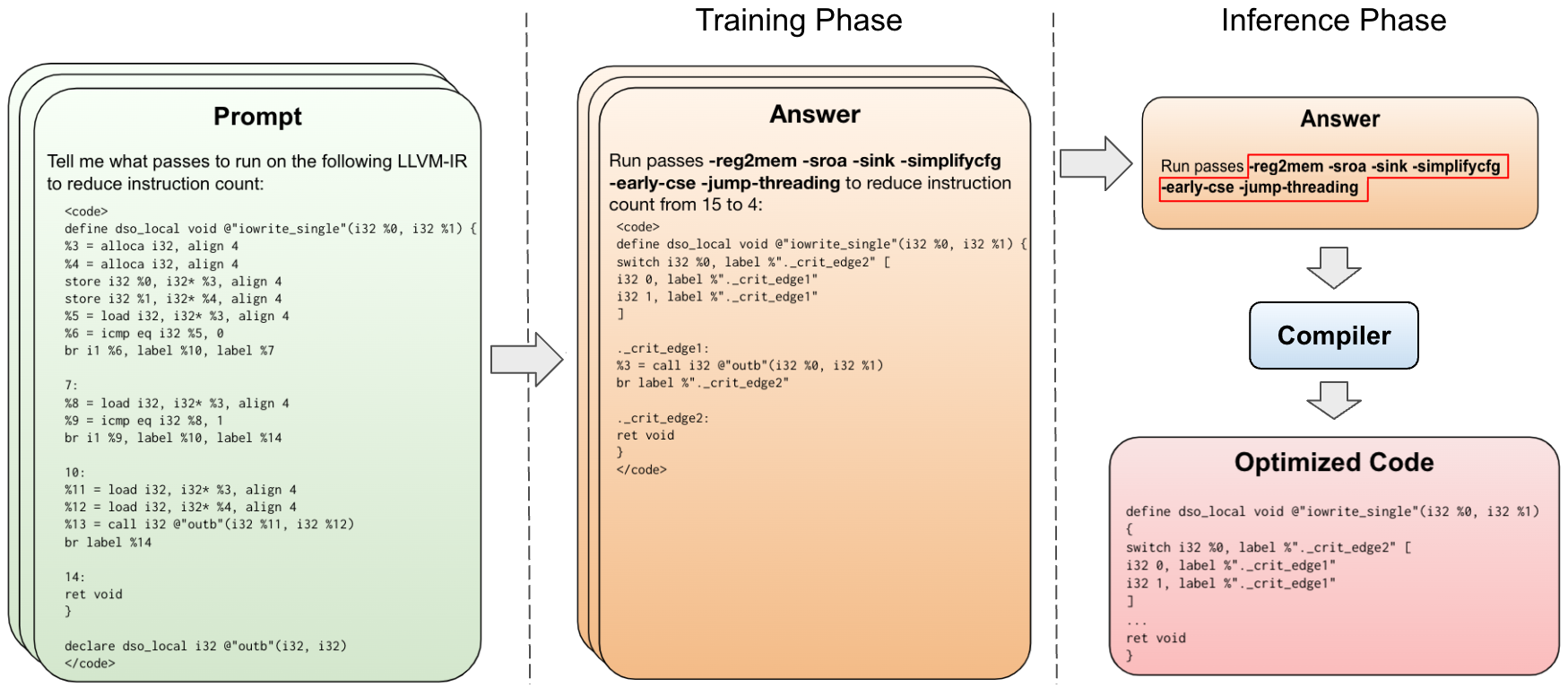
実験結果
リサーチクエスチョン
- RQ1未知コードの命令数を最小化する効果的な LLVM 最適化パスリストを予測することを、LLMは学習できるか?
- RQ2補助タスク(命令数予測と最適化済みIRの生成)はモデルの最適化性能を改善するか?
- RQ3最先端のMLベースラインとオートチューニングと比較して、LLMベースのパス順序付けアプローチは命令削減とコード品質の点でどうか?
- RQ4未知のベンチマークにおけるモデル生成コードとパスリストの特性と制約は何か?
主な発見
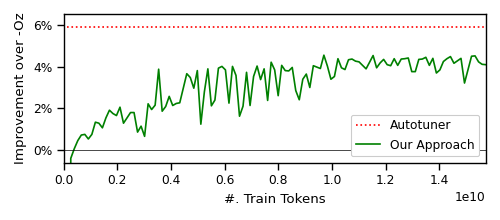
- モデルは、推論時にコンパイラを呼び出さず、完全にモデルによって生成されたパスリストを使用して、コンパイラベースライン(-Oz)に対する命令数削減を3.0%改善した。
- モデル生成の最適化IRの91%がコンパイル可能で、コンパイラ生成の最適化IRとの完全一致は70%。
- 最適化コードのピーク時の BLEU スコア 0.952 と 4.4% の命令削減、オートチューナーは 5.6% を達成するが、膨大なコンパイル作業を要する。
- 未知のベンチマーク全体で、モデルは -Oz、AutoPhase、Coreset-NVP を上回る改善を示し、-Oz のバックアップは回帰を防ぎつつ利得を維持できる。
- モデルは長いまたは大きな入力(大きなプログラムほど改善が大きい傾向)に一般化し、訓練データに存在しない多くの新規パスリストを生成できる(100k のテストプログラムで105個)。
- アブレーションでは、訓練データサイズと、パスリストだけでなく最適化済みコードを生成するようモデルを訓練することが、下流の性能に有意に影響することを示した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。