[論文レビュー] Large Language Models in the Clinic: A Comprehensive Benchmark
この論文は BenchHealth を紹介します。医療推論、生成、理解の5つの信頼指向指標と人間評価を用いて16の LLM を評価する医療ベンチマーク。
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and clinical tasks that are complex but common in real-world practice, e.g., open-ended decision-making, long document processing, and emerging drug analysis. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs. The benchmark data is available at https://github.com/AI-in-Health/ClinicBench.
研究の動機と目的
- 臨床現場における LLM の信頼できる展開を促進するため、close-ended QA を超えてオープンエンドの医療タスクへ移行する。
- 推論、生成、理解の各領域にまたがる公開データセットを用いて、多様な医療タスクにおける LLM をベンチマークする。
- 従来のマッチング指標に加え、追加の信頼性指向指標(忠実度、網羅性、堅牢性、一般化可能性)を導入する。
- 一般的な LLM と医療 LLM、オープンソースと商用モデルの比較分析を提供する。
- 臨床的有用性と限界を評価するために、医療専門家を人間評価に参加させる。
提案手法
- BenchHealth を、医療言語推論、生成、理解の3つのシナリオにまたがる7つのタスクと13の公開データセットで構築する。
- ゼロショットおよび少数ショット(1/3/5ショット)設定で、16 の LLM(一般系9、医療系7)を評価する。
- 正確度に加えて、5つの指標を使用する:忠実度、網羅性、堅牢性、一般化可能性、従来のマッチング指標。
- 最先端のプロンプトに基づいて、各タスクに適したプロンプトを取り入れ、タスク理解を最適化する。
- 患者会話を対象に、医療専門家とともに公開モデルと有力な商用 LLM を比較する人間評価を実施する。
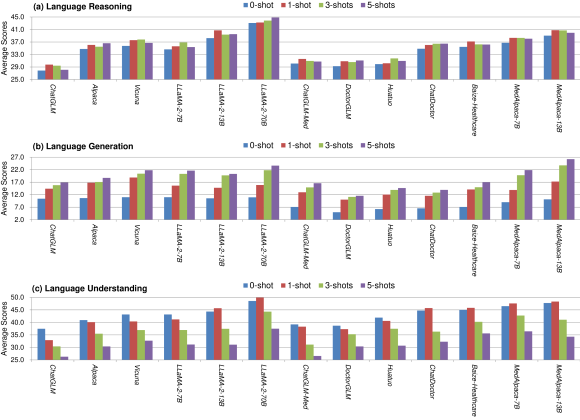
実験結果
リサーチクエスチョン
- RQ1オープンエンドの臨床タスク(推論、生成、理解)は、クローズドな QA と比較して LLM の性能にどのような差を生むか。
- RQ2商用 LLM は医療タスク全般でオープンソースモデルを上回るか、医療向け微調整済み LLM は一般 LLM と比べてどうか。
- RQ3モデルサイズ、微調整データ、少数ショット学習が性能・信頼性・臨床的有用性にどう影響するか。
- RQ4臨床文脈で忠実度、網羅性、堅牢性、一般化可能性を最も適切に捉える指標はどれか。
- RQ5人間評価によると、一般 LLM と医療 LLM の相対的な臨床的有用性はどの程度か。
主な発見
- 商用 LLM(例: GPT-4)は、タスクとデータセット全体でオープンソースモデルを上回る。
- 全ての LLM はクローズドQAに優れるが、オープンエンドの臨床意思決定や一部の生成/理解タスクには苦戦する。
- 一般 LLM を医療データでファインチューニングすると推論/理解は向上するが、要約能力が低下することがある。
- パラメータ数が多いほど、タスク全般で性能が向上する傾向。少数ショットは推論と生成を高めるが、理解には悪影響を及ぼすことがある。
- 医療 LLM はより忠実な回答とより良い一般化可能性を提供する一方、一般 LLM はより広範な網羅性と堅牢性を提供する。
- 人間評価は、医療 LLM が忠実度と一般化可能性で一般 LLM を上回る一方、網羅性と堅牢性では一般 LLM に及ばないことを示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。