[論文レビュー] Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey
この調査は、予測、データ生成、表の理解タスクを通じて、LLMsが表形式データに適用される方法をレビューし、技術の分類、データセット、指標、今後の方向性を提供する。
Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques, metrics, datasets, models, and optimization approaches in this research domain. This survey aims to address this gap by consolidating recent progress in these areas, offering a thorough survey and taxonomy of the datasets, metrics, and methodologies utilized. It identifies strengths, limitations, unexplored territories, and gaps in the existing literature, while providing some insights for future research directions in this vital and rapidly evolving field. It also provides relevant code and datasets references. Through this comprehensive review, we hope to provide interested readers with pertinent references and insightful perspectives, empowering them with the necessary tools and knowledge to effectively navigate and address the prevailing challenges in the field.
研究の動機と目的
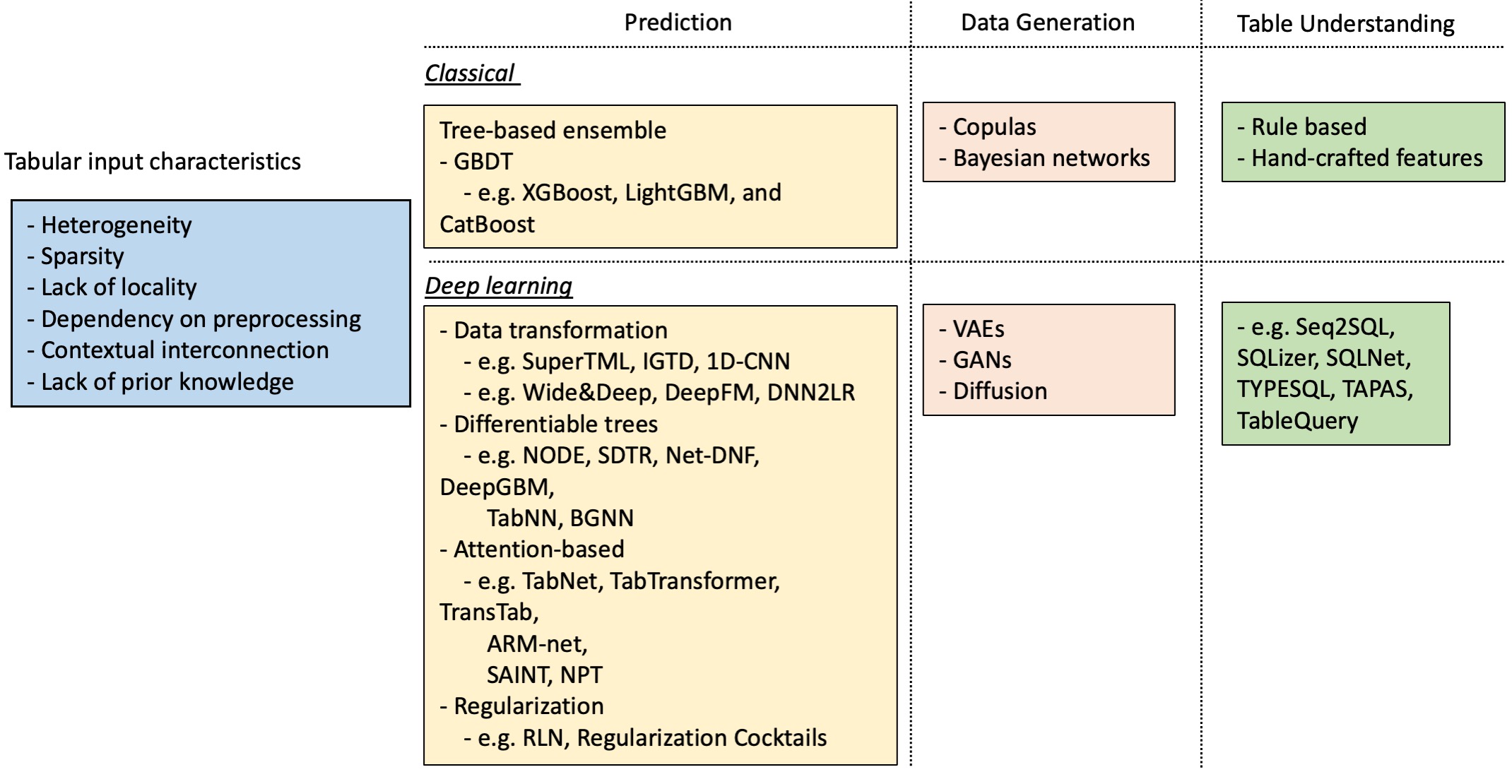
- 表形式データの特性と課題、および従来手法の概要をまとめる。
- 予測、生成、QA、理解などのタスクにおいて、LLMsを表形式データへ適応させる技術の分類体系を提案する。
- 表形式データに対するLLMsで用いられるデータセットと評価指標をレビューし、タスクに対応づける。
- 分野の制限点、ギャップ、将来の研究方向を特定する。
- 実務者向けの関連コードとデータセットの参照情報を提供する。
提案手法
- 表形式データに対するLLMsで用いられるデータセット、指標、手法の調査と分類を行う。
- 技術を、シリアライゼーション、表操作、プロンプト設計、エンドツーエンドのシステム設計に分類する。
- LLMsが予測、データ拡張/生成、質問応答/表理解のためにどのように活用されるかを議論する。
- 頑健性、摂動、表構造および前処理がLLMの性能に与える影響を分析する。
- 実用的な参照とともに、未解決の問題と将来の研究方向を総合する。

実験結果
リサーチクエスチョン
- RQ1どのような技術が、タスクを横断して表形式データに対するLLMsの有効な活用を可能にするか?
- RQ2データセットを跨いで、表形式データに対する予測、生成、QAタスクでLLMsはどのように性能を示すか?
- RQ3LLMベースの表形式データ手法を最も適切にベンチマークするデータセットと指標は何か?
- RQ4表形式データに対するLLMsの主な制約と今後の方向性は何か?
主な発見
- LLMsは、表形式データタスクに活用できるインコンテキスト学習と指示従い能力を提供する。
- シリアライゼーション形式と入力表現の選択は、性能とトークン効率に大きく影響する。HTML/XML形式はGPT系モデルの支援になることがあるが、トークン使用量を増加させる。
- プロンプト設計、チェーン・オブ・思考戦略、自己整合性、および情報取得強化生成は、特に大規模モデルで表形式タスクの性能を向上させる。
- 従来の表形式データのベースラインである勾配ブースト木は予測の強力なベンチマークとして残るが、深層学習は非常に大規模なデータセットや高度にカテゴリ化されたデータセットで優れる場合がある。
- 本論文はデータセット、指標、技術の体系的な分類を提供し、偏り、幻覚、数値データの表現、解釈性、標準化されたベンチマークなどの未解決問題を指摘している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。