[論文レビュー] Large language models surpass human experts in predicting neuroscience results
LLMsは将来予測ベンチマーク BrainBench で神経科学の専門家を上回り、BrainGPT(LoRA微調整)によってさらなる成果を上げた;モデルは自信をキャリブレーションでき、要旨全体の情報を統合可能。
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
研究の動機と目的
- 膨大な文献を活用して、LLMs が実験的神経科学の結果を予測できるかを研究する動機付け。
- 神経科学のアブストラクトに対する一般的なLLMの将来予測能力を人間の専門家と比較して評価する。
- 将来予測におけるモデルの自信度と正確性の関係を評価する。
- 特化した神経科学のファインチューニング(BrainGPT)が予測性能を向上させるかを調査する。
提案手法
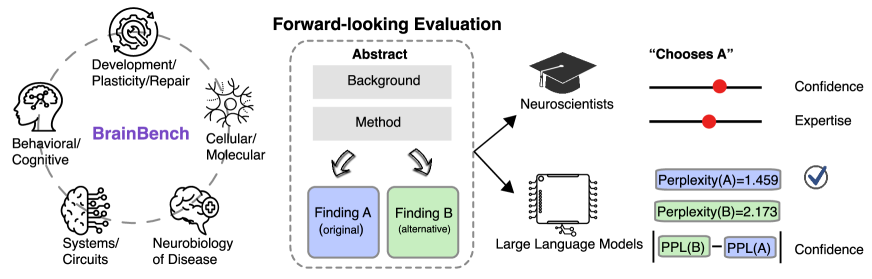
- Journal of Neuroscience からの元の要旨と改変済み要旨という二つの要旨を用いた前向きベンチマーク BrainBench を作成する(5つの領域)。
- 複数の汎用LLMと人間の専門家を評価し、元の要旨を選択させる。
- 予測をパープレキシティを比較して評価。パープレキシティが低い方を元の要旨として選択。
- 自信度(パープレキシティ差)と正確性の相関をとらえてキャリブレーションを評価。
- LoRA を用いて神経科学データで事前学習済み LLM(Llama-2-7B)を微調整し BrainGPT を作成、性能変化を測定する。

実験結果
リサーチクエスチョン
- RQ1LLMs は前向きなベンチマークで神経科学研究の結果を人間の専門家より良く予測できるか?
- RQ2特化した神経科学のファインチューニング(BrainGPT)は、ベースのLLMsを上回る前向き予測性能を改善するか?
- RQ3LLM の予測はキャリブレーションされているか,すなわち高い自信が高い正確性と相関するか?
- RQ4LLMs は結果を予測する際、方法論や背景を跨いだ要旨全体の情報を統合しますか、それとも局所的なテキストのみに頼りますか?
主な発見
- LLMsは平均81.4%の正確度で、人間の専門家63.4%を上回った。
- 人間専門家の上位20%は66.2%の正確度を達成したが、依然としてLLMの性能を下回る。
- 小型モデル(例:Llama2-7B、Mistral-7B)は大規模モデルと同程度の性能だった。
- チャット/指示調整された派生モデルは基盤モデルを下回り、会話的整合性が科学的推論を害する可能性を示唆。
- BrainGPT(LoRA微調整)は、基盤モデルに対してBrainBenchの性能を3%向上させた。
- LLMsは局所的な結果の箇所だけでなく、要旨全体の情報を統合して優れた予測を達成した。
- LLMsの自信度は正確性と正の相関を示した(キャリブレーションされた予測)。
- BrainBench の項目には記憶化の信号は見られず、モデルが新規項目へ一般化することを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。