[論文レビュー] Large Language Models to Enhance Bayesian Optimization
LLAMBO は大規模言語モデルとベイズ最適化を統合し、ゼロショットのウォームスタートを通じてハイパーパラメータチューニングを改善し、インコンテキスト学習を介した代理モデルを強化し、高潜在点を条件付きサンプリングします。
Bayesian optimization (BO) is a powerful approach for optimizing complex and expensive-to-evaluate black-box functions. Its importance is underscored in many applications, notably including hyperparameter tuning, but its efficacy depends on efficiently balancing exploration and exploitation. While there has been substantial progress in BO methods, striking this balance remains a delicate process. In this light, we present LLAMBO, a novel approach that integrates the capabilities of Large Language Models (LLM) within BO. At a high level, we frame the BO problem in natural language, enabling LLMs to iteratively propose and evaluate promising solutions conditioned on historical evaluations. More specifically, we explore how combining contextual understanding, few-shot learning proficiency, and domain knowledge of LLMs can improve model-based BO. Our findings illustrate that LLAMBO is effective at zero-shot warmstarting, and enhances surrogate modeling and candidate sampling, especially in the early stages of search when observations are sparse. Our approach is performed in context and does not require LLM finetuning. Additionally, it is modular by design, allowing individual components to be integrated into existing BO frameworks, or function cohesively as an end-to-end method. We empirically validate LLAMBO's efficacy on the problem of hyperparameter tuning, highlighting strong empirical performance across a range of diverse benchmarks, proprietary, and synthetic tasks.
研究の動機と目的
- LLMs がインコンテキスト学習を用いてベイズ最適化の主要な構成要素(代理モデル、候補点サンプラー)を強化できるかを探る。
- LLAMBO フレームワークを、LLM のファインチューニングを必要としないモジュラーでエンドツーエンドの形で開発する。
- 観測データが希薄な場合でも、LLAMBO が早期段階の BO パフォーマンスを改善することを実証する。
- 既存の BO パイプラインへハイパーパラメータチューニングを組み込む際、LLAMBO を統合できることを示す。
提案手法
- BO コンポーネントを自然言語プロンプトへ翻訳し、ゼロショットおよび少数ショット設定で LLM を活用する。
- インコンテキスト学習を用いた識別的(p(s|h;Dn))および生成的(p(h|s;Dn))代理モデリングを、MC サンプリングによる不確実性の評価とともに用いる。
- ターゲット値 s′ を条件とした候補点を導くサンプリング機構を実装し、インコンテキスト学習に導かせる。
- 問題の記述、データ/モデルカード、シャッフルされたインコンテキスト例を含むプロンプト設計によるロバスト性の促進。
- GPT-3.5 を用いた Bayesmark におけるハイパーパラメータチューニングで LLAMBO を評価し、GP-SM の代替案やアブレーションと比較。
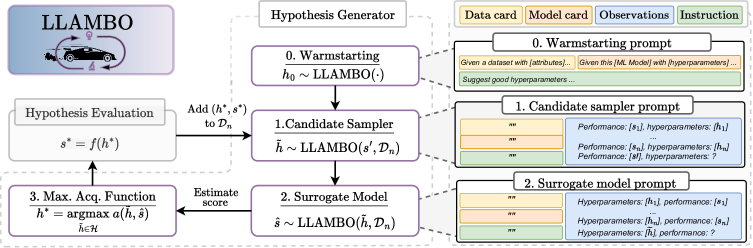
実験結果
リサーチクエスチョン
- RQ1LLMs がインコンテキスト学習を通じて、ベイズ最適化における代理モデルと候補点サンプラーを強化できるか。
- RQ2LLAMBO で拡張した BO コンポーネント が、エンドツーエンドのパイプラインとしてどの程度効果的に協働できるか。
- RQ3LLM の事前分布を用いたゼロショット・ウォームスタートが BO の性能にどのような利益をもたらすか。
- RQ4LLAMBO はLLM のファインチューニングなしで、多様なベンチマークやタスクに対して性能を維持できるか。
主な発見
- LLAMBO はランダムよりもゼロショットのウォームスタートを改善し、データセットのコンテキストが初期探索のパフォーマンスを向上させる。
- 識別的な LLAMBO は、サンプル数に対する予測でベースラインを上回り、n>5 での利用がより良いエクスプロレーションを示す。
- 生成的 LLAMBO(p(h|s;Dn))は、特に少ないサンプル数でスコア相関と後悔の低下をもたらす。
- ターゲット s′ を条件とするサンプリング手法は高品質な点を生み出す可能性があり、α が探索と活用のバランスを取る。
- エンドツーエンドの LLAMBO は、公開データセットとプライベート/合成データセットを問わず、ベイズマークでの最適化パフォーマンスを最も良く改善し、特に初期の探索段階で効果を発揮する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。