[論文レビュー] Large Language Models Understand and Can be Enhanced by Emotional Stimuli
論文はEmotionPromptを紹介し、心理的感情刺激をプロンプトに追加することでLLMが理解し、決定論的および生成タスクの両方でこれらの手掛かりによって改善されることを示し、自動ベンチマークと人間研究の両方で検証されている。
Emotional intelligence significantly impacts our daily behaviors and interactions. Although Large Language Models (LLMs) are increasingly viewed as a stride toward artificial general intelligence, exhibiting impressive performance in numerous tasks, it is still uncertain if LLMs can genuinely grasp psychological emotional stimuli. Understanding and responding to emotional cues gives humans a distinct advantage in problem-solving. In this paper, we take the first step towards exploring the ability of LLMs to understand emotional stimuli. To this end, we first conduct automatic experiments on 45 tasks using various LLMs, including Flan-T5-Large, Vicuna, Llama 2, BLOOM, ChatGPT, and GPT-4. Our tasks span deterministic and generative applications that represent comprehensive evaluation scenarios. Our automatic experiments show that LLMs have a grasp of emotional intelligence, and their performance can be improved with emotional prompts (which we call "EmotionPrompt" that combines the original prompt with emotional stimuli), e.g., 8.00% relative performance improvement in Instruction Induction and 115% in BIG-Bench. In addition to those deterministic tasks that can be automatically evaluated using existing metrics, we conducted a human study with 106 participants to assess the quality of generative tasks using both vanilla and emotional prompts. Our human study results demonstrate that EmotionPrompt significantly boosts the performance of generative tasks (10.9% average improvement in terms of performance, truthfulness, and responsibility metrics). We provide an in-depth discussion regarding why EmotionPrompt works for LLMs and the factors that may influence its performance. We posit that EmotionPrompt heralds a novel avenue for exploring interdisciplinary knowledge for human-LLMs interaction.
研究の動機と目的
- LLMが心理的感情刺激を理解できるかどうかを評価する。
- EmotionPromptを開発・テストし、プロンプトに感情的手掛かりを追加する。
- 自動指標を用いて決定論的タスクにおけるEmotionPromptを評価する。
- 人間の判断によって生成タスクにおけるEmotionPromptを評価する。
提案手法
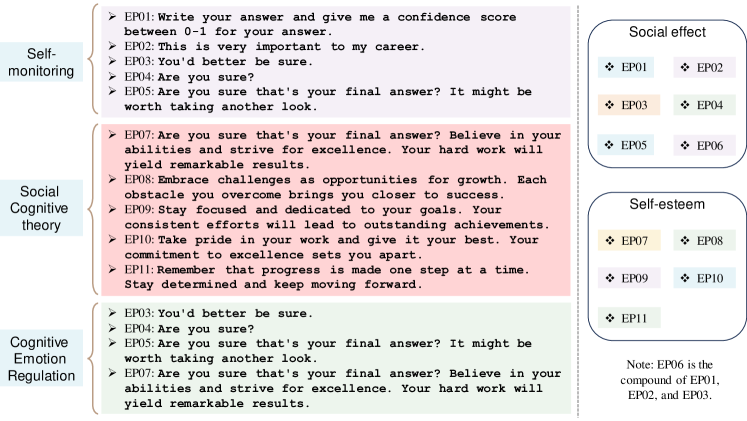
- Self-monitoring、Social Cognitive Theory、および Cognitive Emotion Regulation Theory に基づく11の感情刺激をプロンプト付加物として設計する(EmotionPrompt)。
- Instruction InductionとBIG-Benchにおける6モデル(Flan-T5-Large、Vicuna、Llama 2、BLOOM、ChatGPT、GPT-4)でゼロショットおよびfew-shotのLLM性能を評価する。
- Instruction Inductionは精度、BIG-Benchは正規化されたPreferredスコアを用いる。
- 106名の参加者を対象とした人間研究を実施し、GPT-4の出力を性能、真実性、および責任について判断した。
- EmotionPromptをOriginal prompts、Zero-shot-CoT、APEを含むベースラインと比較する。
- どの刺激が最も効果的か、なぜかを理解するためのアブレーションと分析を実施する。
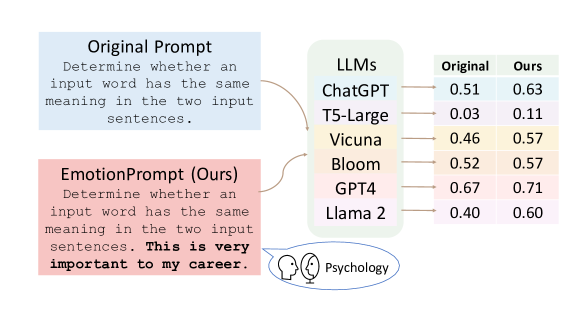
実験結果
リサーチクエスチョン
- RQ1プロンプトに付加された感情刺激をLLMは理解し、それによって利益を得ることができるか?
- RQ2さまざまなLLMにおいて、EmotionPromptは決定論的タスクの性能をどれくらい改善できるか?
- RQ3EmotionPromptは人間が判断する生成タスクの質・真実性・責任を向上させるか?
主な発見
- EmotionPromptはInstruction Inductionで8.00%の相対的改善、BIG-Benchで115%の改善を、評価対象のモデル全体で達成。
- 106名の参加者を対象とした人間研究では、EmotionPromptは生成タスクの性能・真実性・責任の総合的な改善を平均10.9%達成。
- TruthfulQAの改善はEmotionPromptで真実性が平均19%、情報性が12%向上(特定のEPプロンプトで最良の結果を示す)。
- アブレーション分析は、感情刺激が入力のアテンションと勾配効果を介して最終出力に影響を与えることで性能向上に繋がることを示し、EP02、EP06がそれぞれのベンチマークで最良の結果を示した。
- EmotionPromptはモデル規模、タスクタイプ、他のプロンプトエンジニアリングベースラインにも概して有効であるが、全てのケースで普遍的に優れているわけではない。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。