[論文レビュー] LayoutGPT: Compositional Visual Planning and Generation with Large Language Models
LayoutGPTはCSS風のインコンテキストプロンプトを用いてLLMを視覚的プランナーに変換し、領域制御付き画像生成モデルと組み合わせた際に、忠実度と効率を向上させる2Dレイアウトと3D室内シーンレイアウトを生成します。
Attaining a high degree of user controllability in visual generation often requires intricate, fine-grained inputs like layouts. However, such inputs impose a substantial burden on users when compared to simple text inputs. To address the issue, we study how Large Language Models (LLMs) can serve as visual planners by generating layouts from text conditions, and thus collaborate with visual generative models. We propose LayoutGPT, a method to compose in-context visual demonstrations in style sheet language to enhance the visual planning skills of LLMs. LayoutGPT can generate plausible layouts in multiple domains, ranging from 2D images to 3D indoor scenes. LayoutGPT also shows superior performance in converting challenging language concepts like numerical and spatial relations to layout arrangements for faithful text-to-image generation. When combined with a downstream image generation model, LayoutGPT outperforms text-to-image models/systems by 20-40% and achieves comparable performance as human users in designing visual layouts for numerical and spatial correctness. Lastly, LayoutGPT achieves comparable performance to supervised methods in 3D indoor scene synthesis, demonstrating its effectiveness and potential in multiple visual domains.
研究の動機と目的
- LLMを用いてテキスト条件から2Dおよび3D生成の視覚レイアウトを計画できるようにする。
- 細かな入力を言語駆動のレイアウト計画に置換することでユーザーの負担を軽減する。
- インコンテキストデモンストレーションとCSS風プロンプトがLLMに視覚的常識を注入することを示す。
- 2D T2Iと3D室内シーン合成におけるレイアウト忠実度と画像/シーン品質をベンチマークする。
- 3D室内シーンタスクにおいて最先端の監視付き手法と競合できることを示す。
提案手法
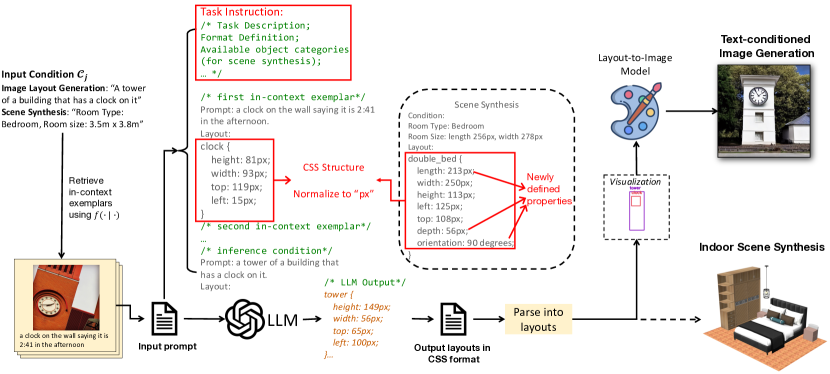
- レイアウトをCSS風の形式で構造化されたプログラムとして表現し、LLMに空間的意味を明確化する。
- 学習を助けるためにタスク指示を先頭に付け、値を一貫したスケール(最大256px)に正規化する。
- 類似性に基づいてインコンテキストの実例を選択する(2DプロンプトはCLIPベース、3Dは部屋サイズの差異)、そして例を逆順で提示する。
- LLM生成レイアウトを下流のlayout-to-imageまたは3Dシーンレンダリングモデルと組み合わせ、最終ビジュアルを生成する。
- 家具のカテゴリ、位置、サイズ、向きを予測して3D室内シーン合成へ拡張し、続いてレンダリングを行う。
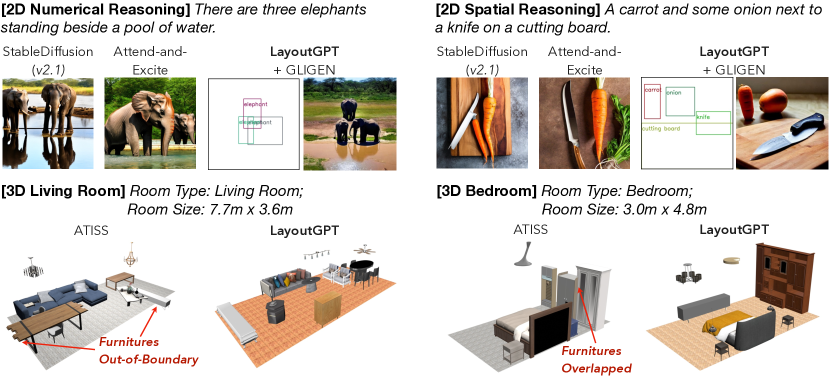
実験結果
リサーチクエスチョン
- RQ1CSS風のレイアウトに導かれたとき、LLMはテキストプロンプトから忠実なオブジェクト数と空間関係を生成できるか?
- RQ2インコンテキストのCSS構造化プロンプトは、平文プロンプトよりレイアウトの忠実度と下流の画像品質を向上させるか?
- RQ3微調整なしで2D画像レイアウトから3D室内シーン合成へLayoutGPTはどれだけスケールするか?
- RQ4タスク指示、CSS形式、値の正規化が2Dおよび3Dタスクのレイアウト精度に与える影響はどれくらいか?
主な発見
- LayoutGPTはGLIPベースのレイアウト精度で2D生成においてエンドツーエンドのテキスト-画像モデルを20-40%上回る。
- LayoutGPTは数値的および空間的正確さにおいて、2Dレイアウトの人間作成レイアウトと同等の性能を達成する。
- LayoutGPTは3D室内シーン合成において、ベッドルームとリビングルームのシーンで平均メトリクス(例:FID、アウト・オブ・ボウンド)に基づく競合的または優れた結果を達成する。
- アブレーション研究は、CSS形式のインコンテキストデモンストレーションと正規化がレイアウト忠実度にとって重要であり、CSSが大きな利点をもたらすことを示している。
- LayoutGPTは密なレイアウト、テキストベースのインペインティング、反事実プロンプトに対して堅牢な性能を示し、強い視覚的常識と一般化能力を示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。