[論文レビュー] Leak, Cheat, Repeat: Data Contamination and Evaluation Malpractices in Closed-Source LLMs
この論文は、公開された研究を通じたOpenAI GPT-3.5およびGPT-4へのデータ汚染と評価慣行の不正を体系的に分析し、約42%の漏洩があり totaling ~4.7 million samples across 263 benchmarks に及ぶことを発見し、再現性と公平性の課題を浮き彫りにしています。
Natural Language Processing (NLP) research is increasingly focusing on the use of Large Language Models (LLMs), with some of the most popular ones being either fully or partially closed-source. The lack of access to model details, especially regarding training data, has repeatedly raised concerns about data contamination among researchers. Several attempts have been made to address this issue, but they are limited to anecdotal evidence and trial and error. Additionally, they overlook the problem of \emph{indirect} data leaking, where models are iteratively improved by using data coming from users. In this work, we conduct the first systematic analysis of work using OpenAI's GPT-3.5 and GPT-4, the most prominently used LLMs today, in the context of data contamination. By analysing 255 papers and considering OpenAI's data usage policy, we extensively document the amount of data leaked to these models during the first year after the model's release. We report that these models have been globally exposed to $\sim$4.7M samples from 263 benchmarks. At the same time, we document a number of evaluation malpractices emerging in the reviewed papers, such as unfair or missing baseline comparisons and reproducibility issues. We release our results as a collaborative project on https://leak-llm.github.io/, where other researchers can contribute to our efforts.
研究の動機と目的
- 公開された研究を通じたGPT-3.5およびGPT-4への間接的なデータ汚染(データ漏洩)の定量化。
- 漏洩データがさらなる学習にどのように利用され得るかと、それが公平な比較・評価に及ぼす影響の評価。
- クローズドソースLLMを用いた研究における普遍的な評価不正行為と再現性の障壁の特定。
- クローズドソースLLMの評価厳密性を改善するためのベストプラクティスの提案。
提案手法
- GPT-3.5およびGPT-4を評価した255件の論文の系統的文献調査を実施。
- ウェブインターフェース対APIアクセスを用いた論文を特定し、OpenAIのデータ使用ポリシーへのデータ漏洩の潜在的影響をマッピング。
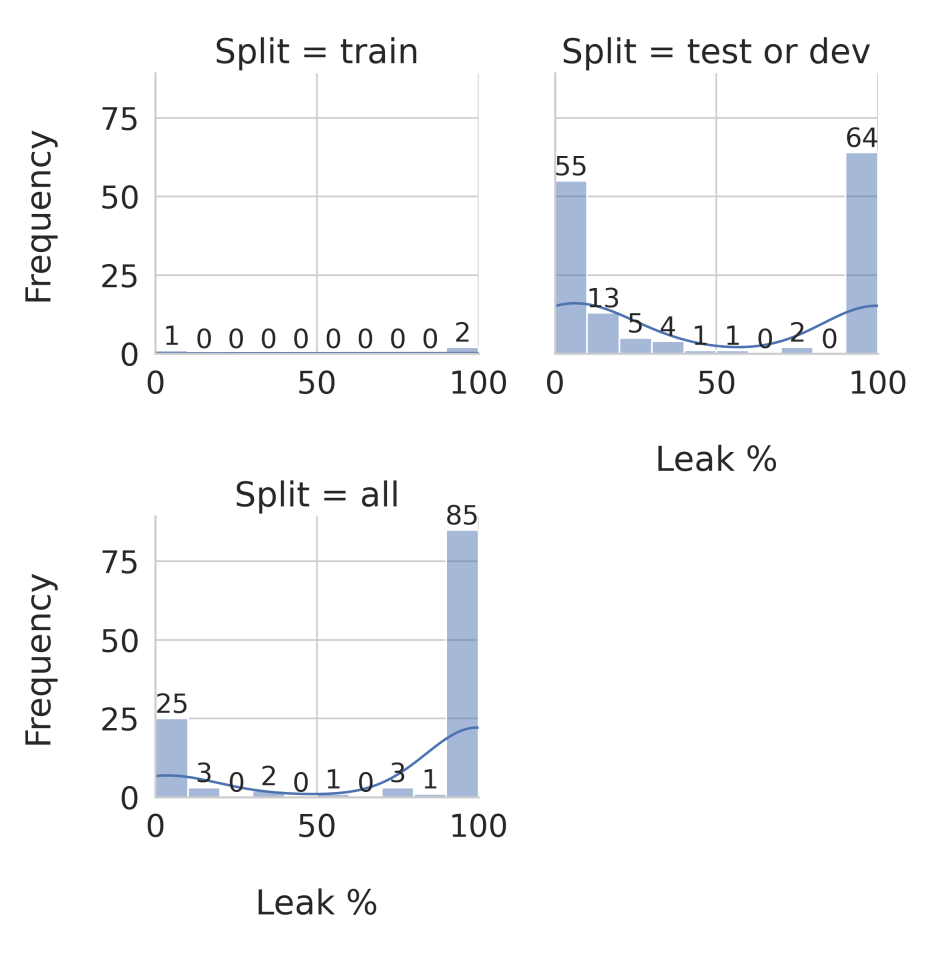
- 報告されたデータセットとスプリットごとに漏洩データを推定し、そうでない場合はデータセット全体の使用を仮定。
- 再現性のため、プロンプトの可用性、コードリポジトリ、データセットのスプリット、モデルバージョンの報告を評価。
- ベースラインとの比較を通じた評価の公平性を分析し、モデル間で同等のデータ使用を保証。
実験結果
リサーチクエスチョン
- RQ1この1年でGPT-3.5およびGPT-4に対して実証的に漏洩したデータセットはどれか。
- RQ2これらのモデルを評価する論文は既存のベースラインと公正な比較を含んでいるか。
- RQ3クローズドソースLLM評価における再現性と公正性を損なう普遍的な慣行は何か。
- RQ4クローズドソースLLMのデータ汚染と評価不正を緩和するためのガイドラインは何か。
主な発見
- ~42%のレビュー論文がGPT-3.5またはGPT-4にデータを漏洩しており、263のベンチマーク全体で ~4.7 million samples に達する。
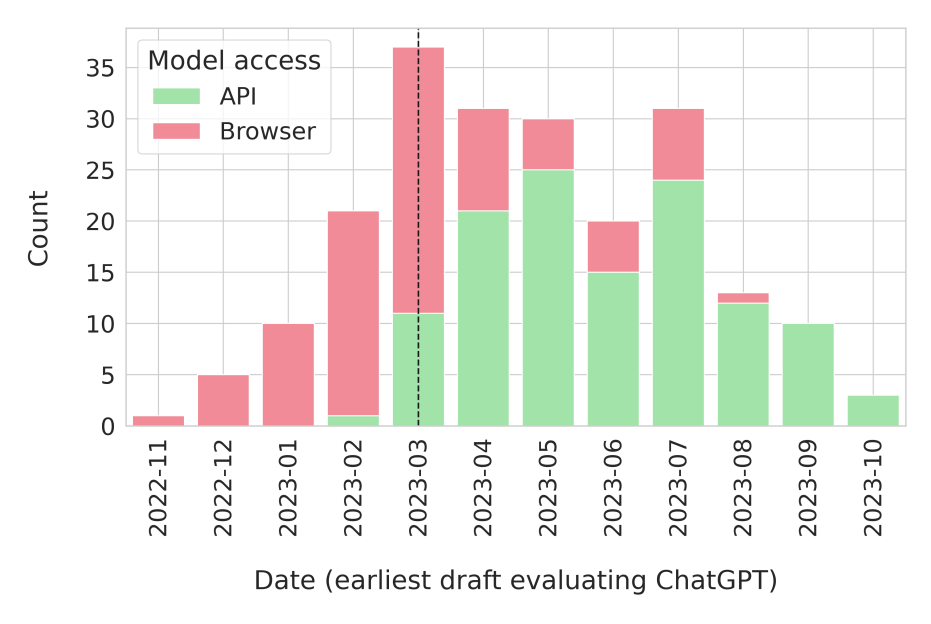
- 90 papers (~42%) accessed ChatGPT via the web interface, exposing data OpenAI could use for training.
- Datasets leaked were spread across tasks, with high leak counts in natural language inference, question answering, and natural language generation.
- Only ~91% reported prompts used; ~53% provided a code repository; only 40%/23% provided model version details for peer‑reviewed/preprint papers respectively.
- Many studies performed unfair or incomplete comparisons, often evaluating ChatGPT on fewer samples than open models and on different data sizes.
- A collaborative public resource (leak-llm.github.io) was released to document leaks and encourage community contributions.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。