[論文レビュー] Leak Proof PDBBind: A Reorganized Dataset of Protein-Ligand Complexes for More Generalizable Binding Affinity Prediction
本論文は LP-PDBBind を導入し、PDBBind のクリーンでリーク防止の再編成を行い、それに基づいて4つのスコアリング関数を再訓練し、3D構造ベースの手法など独立ベンチマーク(BDB2020+ など)で汎化の改善を示す一方、純粋にシーケンスベースのモデルには限定的な利益しかない点を指摘する。
Many physics-based and machine-learned scoring functions (SFs) used to predict protein-ligand binding free energies have been trained on the PDBBind dataset. However, it is controversial as to whether new SFs are actually improving since the general, refined, and core datasets of PDBBind are cross-contaminated with proteins and ligands with high similarity, and hence they may not perform comparably well in binding prediction of new protein-ligand complexes. In this work we have carefully prepared a cleaned PDBBind data set of non-covalent binders that are split into training, validation, and test datasets to control for data leakage, defined as proteins and ligands with high sequence and structural similarity. The resulting leak-proof (LP)-PDBBind data is used to retrain four popular SFs: AutoDock Vina, Random Forest (RF)-Score, InteractionGraphNet (IGN), and DeepDTA, to better test their capabilities when applied to new protein-ligand complexes. In particular we have formulated a new independent data set, BDB2020+, by matching high quality binding free energies from BindingDB with co-crystalized ligand-protein complexes from the PDB that have been deposited since 2020. Based on all the benchmark results, the retrained models using LP-PDBBind consistently perform better, with IGN especially being recommended for scoring and ranking applications for new protein-ligand systems.
研究の動機と目的
- PDBBind データセットにおけるデータ漏洩と品質の非均一性に対処するため、クリーンで非共有結合のリーク防止分割(LP-PDBBind)を作成する。
- LP-PDBBind 上で既存のスコアリング関数を再訓練することが、新規のタンパク質-リガンド複合体への汎化にどのように影響するかを評価する。
- 再訓練モデルの転移性能を評価する独立したベンチマーク(BDB2020+)を提供する。
- リーク防止データ分割および3D構造ベース表現から最も恩恵を受けるモデルファミリーについての指針を提供する。
提案手法
- PDBBind をクリーン化・フィルタリングして非共有結合の高品質サブセット(CL1、任意で CL2/CL3)を作成し、タンパク質カテゴリー別の類似性ベースのリーク制御分割を定義する。
- Morgan フィンガープリントと Dice 相似度を用いてリガンドの類似性を計算し、カテゴリ内でシーケンスアラインメントによってタンパク質の類似性を計算し、トレイン-テストのリークを最小化する反復的なシードベース分割を適用する。
- LP-PDBBind 上で4つのスコアリングファミリーを再訓練する:AutoDock Vina(3D項を再加重)、RF-Score(原子タイプ接触に基づくランダムフォレスト)、IGN(3D構造のグラフニューラルネットワーク)、DeepDTA(シーケンス/ SMILES ベースのベースライン)。
- 最近の BindingDB レコードを PDB 構造と類似性制御を用いて一致させ、独立した評価ベンチマークである BDB2020+ を構築する。
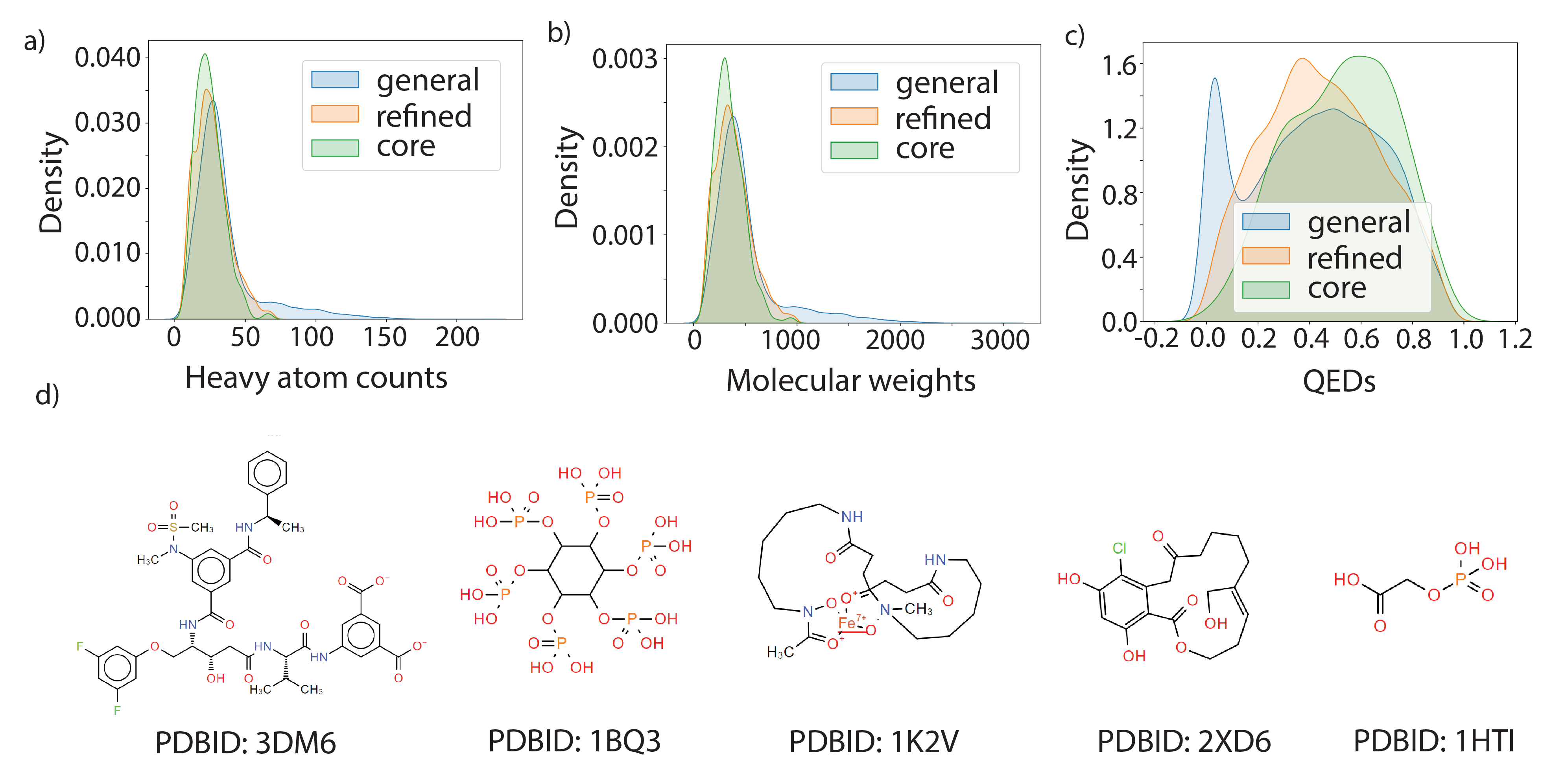
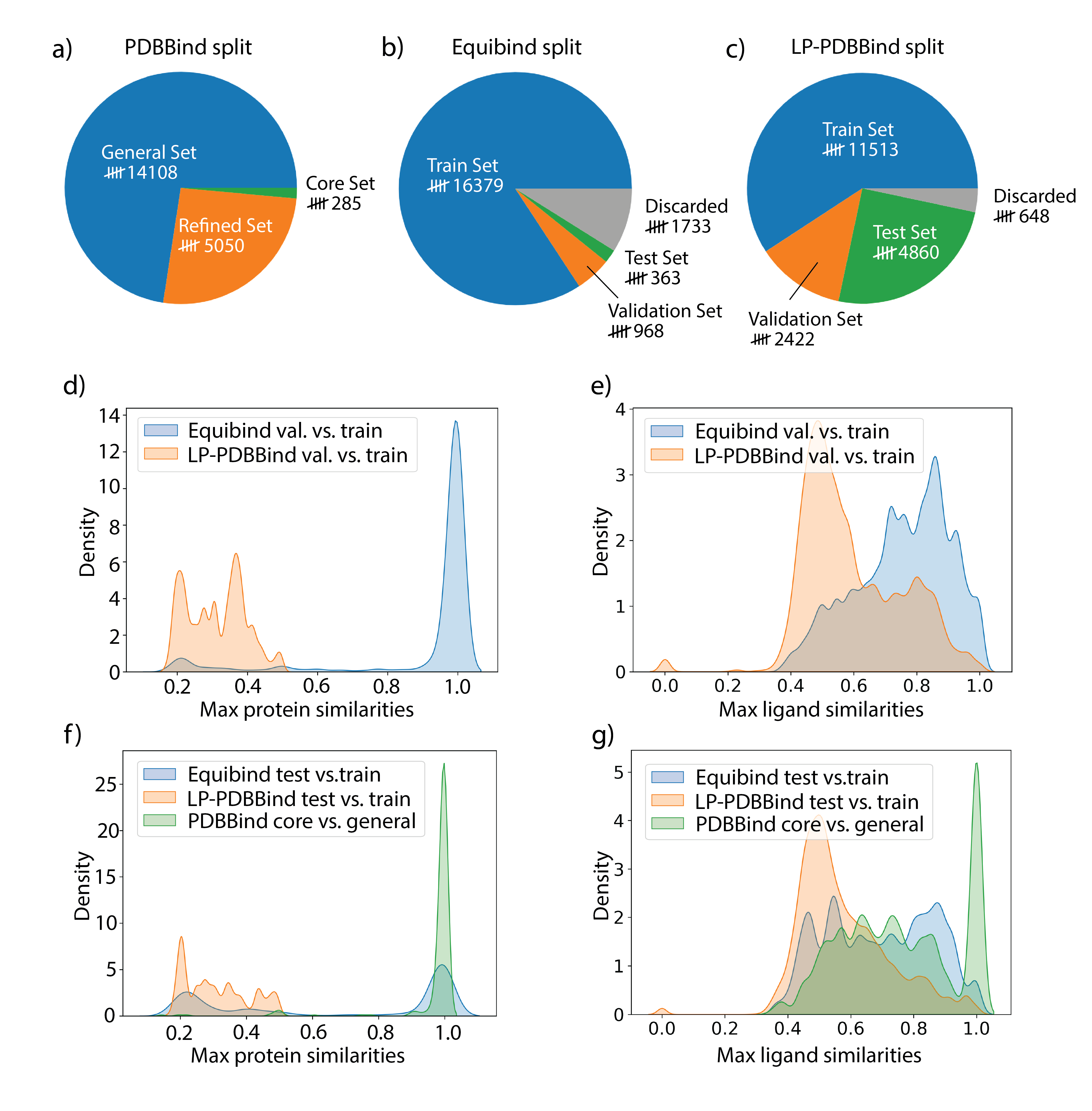
実験結果
リサーチクエスチョン
- RQ1LP-PDBBind によるデータ漏洩の除去は、既存のSFの新規のタンパク質-リガンド複合体への汎化を改善しますか?
- RQ2LP-PDBBind で訓練し独立ベンチマークで評価した場合、3D構造ベースのモデルとシーケンスベースのモデルはどう比較されますか?
- RQ3LP-PDBBind で再訓練することが、訓練・検証・テストセットおよび独立ベンチマーク(例:BDB2020+)のパフォーマンス指標に与える影響は何ですか?
- RQ4リーク防止再訓練後、未知の複合体や独立データセットへの最も堅牢な転移可能性を示すモデルファミリーはどれですか?
主な発見
- LP-PDBBind 上での再訓練は、BDB2020+ のような独立ベンチマークで3D構造ベースのモデル(IGN、AutoDock Vina、RF-Score)を改善し、より良い汎化を示す。
- IGNは再訓練後も新規のタンパク質-リガンド系のスコアリングとランキングで一貫して最上位の成績を示す。
- DeepDTA(1Dシーケンスベース)は再訓練後の汎化が低下し、独立ベンチマークでは3Dベースのモデルと比較して劣る。
- 元の MLSF モデルは学習データの重複のため、リークが生じやすいコアで過大評価される。LP-PDBBind はその真の汎化ギャップを明らかにする。
- LP-PDBBind 分割は訓練データとの類似度を制御したより大きなテストセットを提供し、転移可能性のより現実的な評価を可能にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。