[論文レビュー] Learned Thresholds Token Merging and Pruning for Vision Transformers
LTMP は Learned thresholds を用いた token merging と pruning を組み合わせ、Vision Transformer のトークンを適応的に削減。単一エポックのファインチューニングで、様々な FLOPs 削減時にも高い精度を達成。
Vision transformers have demonstrated remarkable success in a wide range of computer vision tasks over the last years. However, their high computational costs remain a significant barrier to their practical deployment. In particular, the complexity of transformer models is quadratic with respect to the number of input tokens. Therefore techniques that reduce the number of input tokens that need to be processed have been proposed. This paper introduces Learned Thresholds token Merging and Pruning (LTMP), a novel approach that leverages the strengths of both token merging and token pruning. LTMP uses learned threshold masking modules that dynamically determine which tokens to merge and which to prune. We demonstrate our approach with extensive experiments on vision transformers on the ImageNet classification task. Our results demonstrate that LTMP achieves state-of-the-art accuracy across reduction rates while requiring only a single fine-tuning epoch, which is an order of magnitude faster than previous methods. Code is available at https://github.com/Mxbonn/ltmp .
研究の動機と目的
- Vision Transformer の計算量を adaptive token reduction で削減する動機づけ。
- 学習可能な閾値と結合した token merging と pruning のフレームワークを提案。
- 閾値のみにファインチューニングを限定し、予算感知のロスを用いて高速収束を実現。
- DeiT 系列の複数の削減ターゲットで最先端の精度を示す。
提案手法
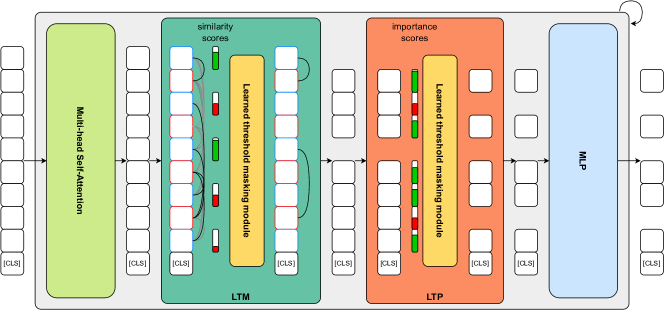
- 各トランスフォーマーブロックの MSA と MLP の間に merging (LTM) と pruning (LTP) モジュールを追加。
- 各層でどのトークンを prune または merge するかを決定するために learned threshold masking を使用。
- pruned/merged トークンを含む masked softmax を導入した注意機構を適用(Attention_with_mask)。
- 所望の FLOPs 削減 r_target をターゲットとし、layer-wise token masks から r_FLOPs を計算する budget-aware training loss を適用。
- 単一エポックの収束を目指して、他のパラメータを固定したまま各ブロックの二つの閾値のみを訓練。
実験結果
リサーチクエスチョン
- RQ1 token merging と pruning を Vision Transformer に組み合わせても精度を損なわずに有効に機能するか。
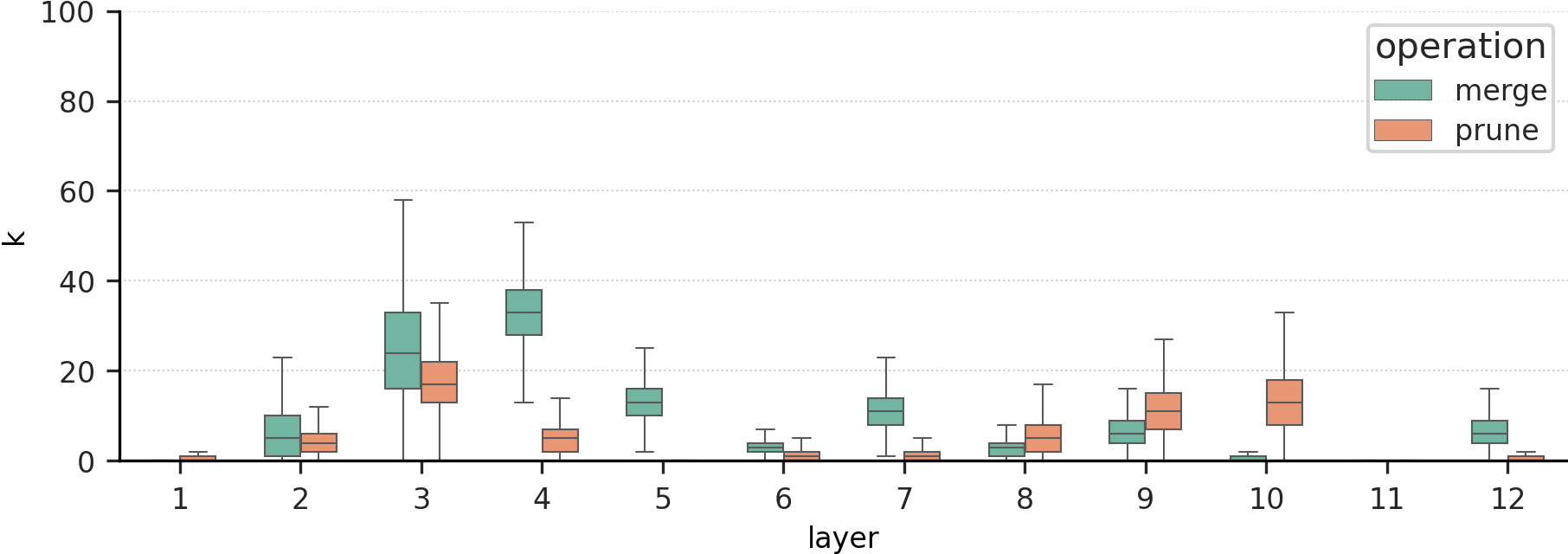
- RQ2 learned thresholds は FLOPs の予算を満たすような層ごとの適応的な token 削減分布を可能にするか。
- RQ3 LTMP は prior の token reduction 手法と比較して、精度と必要なファインチューニングエポック数はどうなるか。
主な発見
- LTMP は様々な token 削減ターゲットで高い精度を達成し、同程度の FLOPs における従来の token pruning を上回る。
- LTMP は単一のファインチューニングエポックで収束し、トランスフォーマーブロックごとに学習可能パラメータは二つのみ。
- budget-aware loss は層間で pruning と merging を効果的に分配し、 r_target の削減を実現。
- LTMP は ToMe や他の learnable pruning 手法と比較して精度-FLOPs のトレードオフが有利で、ファインチューニングエポック数が著しく少ない。
- モバイル機器での推論レイテンシ改善は FLOPs 削減と密接に相関し、DeiT-S で r_FLOPs≈0.5 の場合約50% のレイテンシ削減。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。