[論文レビュー] Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identification
この論文は複数の人の再識別データセットから汎用的な CNN 特徴を学習し、Domain Guided Dropout を導入してドメイン固有ニューロンを抑制することで、複数のデータセットにおいて最先端の結果を達成する。
Learning generic and robust feature representations with data from multiple domains for the same problem is of great value, especially for the problems that have multiple datasets but none of them are large enough to provide abundant data variations. In this work, we present a pipeline for learning deep feature representations from multiple domains with Convolutional Neural Networks (CNNs). When training a CNN with data from all the domains, some neurons learn representations shared across several domains, while some others are effective only for a specific one. Based on this important observation, we propose a Domain Guided Dropout algorithm to improve the feature learning procedure. Experiments show the effectiveness of our pipeline and the proposed algorithm. Our methods on the person re-identification problem outperform state-of-the-art methods on multiple datasets by large margins.
研究の動機と目的
- 複数の偏った人の再識別データセットから頑健な特徴表現を学習する動機づけ。
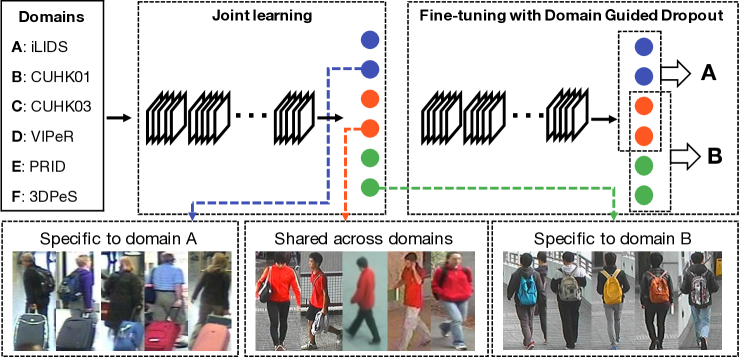
- 複数ドメインを同時に用いて汎用特徴を学習する CNN アーキテクチャと学習パイプラインを提案。
- Domain Guided Dropout を導入し、ドメイン固有ニューロンを抑制してマルチドメイン学習を正則化。
- いくつかの標準的な再識別データセットにおいて、最先端と比較して性能を大きく向上させることを示す。
提案手法
- マージされたマルチドメインデータセット上で CNN を初期学習させ、単一のソフトマックス損失で共有特徴抽出器 g を学習する。
- 各ドメインについて損失に対する平均ニューロン影響を計算し、ドメイン関連ニューロンを同定する。
- 標準 Dropout を Domain Guided Dropout に置換(決定論的または確率的)し、訓練中にドメイン固有ニューロンを抑制する。
- ドメインごとに確率的 Domain Guided Dropout で微調整して、ドメイン固有の性能を最大化する。
- 学習した特徴量に対してユークリッド距離を用いて人の再識別を評価し、ペア-wise 損失を用いたメトリック学習を行わない。

実験結果
リサーチクエスチョン
- RQ1複数のドメインデータセットを統合することで、すべてのドメインで良好に機能する汎用的な CNN 特徴表現を得られるか。
- RQ2ドメイン固有ニューロンが存在し、ドメインごとにマスクすることでクロスドメイン性能を改善できるか。
- RQ3Domain Guided Dropout(決定論的および確率的)は、標準の dropout や JSTL ベースラインと比較して複数データセットで性能を改善するか。
主な発見
| 方法 | CUHK03 | CUHK01 | PRID | VIPeR | 3DPeS | iLIDS |
|---|---|---|---|---|---|---|
| Best | 62.1 | 53.4 | 17.9 | 45.9 | 54.2 | 52.1 |
| Individually | 72.6 | 34.4 | 37.0 | 12.3 | 31.1 | 27.5 |
| JSTL | 72.0 | 62.1 | 59.0 | 35.4 | 44.5 | 56.9 |
| JSTL+DGD | 72.5 | 63.0 | 60.0 | 37.7 | 45.6 | 59.6 |
| FT-JSTL | 74.8 | 66.2 | 57.0 | 37.7 | 54.0 | 61.1 |
| FT-JSTL+DGD | 75.3 | 66.6 | 64.0 | 38.6 | 56.0 | 64.6 |
- 共同訓練済みモデル(JSTL)は、単一ドメインでの訓練と比較して大半のデータセットで性能を向上させる。
- Domain Guided Dropout(DGD)は JSTL 後のドメイン全体の性能を、一貫して 0.5%–2.7% 向上させる。
- 個々のドメインでの確率的 DGD による微調整は、JSTL+DGD より追加の改善をもたらし、ドメイン固有の精度を高める。
- 最良の結果は FT-JSTL+DGD で得られ、いくつかのデータセットで従来の最良手法を上回る。
- 報告された最大の改善は複数データセットを組み合わせた場合に生じ、特に小さなドメインで顕著。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。