[論文レビュー] Learning from Hypervectors: A Survey on Hypervector Encoding
ハイパーベクトルが生成・エンコードされる過程に焦点を当てたHyperdimensional Computingの調査で、データマッピング、エンコード手法、精度と効率に影響を与えるハードウェアの考慮点を検討する。
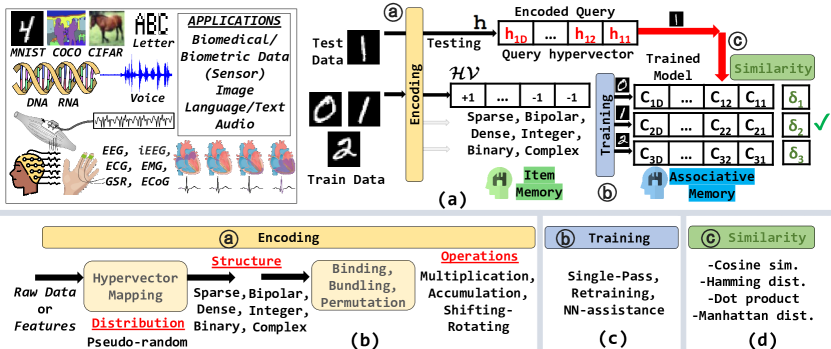
Hyperdimensional computing (HDC) is an emerging computing paradigm that imitates the brain's structure to offer a powerful and efficient processing and learning model. In HDC, the data are encoded with long vectors, called hypervectors, typically with a length of 1K to 10K. The literature provides several encoding techniques to generate orthogonal or correlated hypervectors, depending on the intended application. The existing surveys in the literature often focus on the overall aspects of HDC systems, including system inputs, primary computations, and final outputs. However, this study takes a more specific approach. It zeroes in on the HDC system input and the generation of hypervectors, directly influencing the hypervector encoding process. This survey brings together various methods for hypervector generation from different studies and explores the limitations, challenges, and potential benefits they entail. Through a comprehensive exploration of this survey, readers will acquire a profound understanding of various encoding types in HDC and gain insights into the intricate process of hypervector generation for diverse applications.
研究の動機と目的
- HVがさまざまなデータタイプ(数値、2D、シーケンス等)からどのように生成され、これがモデルの性能にどう影響するかを明確にする。
- 既存のHVエンコード手法(レコードベース、N-gram、スパース/デンス、LDベース)とそれらのトレードオフを調査する。
- HVエンコードのハードウェアおよびエッジ学習への影響を強調する。
- 多様なアプリケーションにおけるHV生成の課題と今後の研究機会を特定する。
提案手法
- 既存のHDC文献からHVマッピングとエンコード手法をレビューし、分類する。
- データ表現全体でのHVの直交性、密度、スパーシティの考慮点を比較する。
- HV生成に関するハードウェアへの影響と最適化戦略を議論する(FPGA、CIM など)。
- 異なるエンコード方式が学習タスクの精度と効率に与える影響を要約する。
実験結果
リサーチクエスチョン
- RQ1異なるデータタイプ(数値、画像、シーケンス)に対するHV生成戦略は何があり、エンコード品質にどう影響するか?
- RQ2エンコードの選択(直交性、密度、スパーシティ、LD/分布)はHDCの精度とハードウェア効率にどう影響するか?
- RQ3アプリケーション全体で、レコードベースとN-gramベースのHV生成手法の主なトレードオフは何か?
- RQ4大規模なHVエンコードをサポートする現在のハードウェア要件とプラットフォーム、特にエッジ学習に焦点を当てて。
- RQ5新興アプリケーションやデータモダリティにおけるHVエンコードの未解決課題は何か?
主な発見
- HV生成の品質とベクトル分布は、HDCの精度と効率に重大な影響を与える。
- 複数のエンコード方式(レコードベース、N-gram、確率的、LDベース)は、精度、ハードウェアコスト、スケーラビリティの間でトレードオフを提供する。
- スパース対デンスHV表現はハードウェア効率に影響し、データタイプ(数値対記号)に合わせて調整可能。
- ハードウェア指向の最適化(FPGA、CIM、オンチップ学習)は、ベースラインアーキテクチャと比較して面積とスループットで大幅な向上をもたらす。
- DNA処理や特定のデータモダリティにおけるHVエンコードには顕著な研究ギャップがあり、今後の課題の機会を示唆している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。