[論文レビュー] Learning from models beyond fine-tuning
Learn From Model (LFM) パラダイムを紹介する包括的な調査で、FM-based 手法をモデル調整、蒸留、再利用、メタ学習、編集の5領域に分類し、データではなくモデルから学ぶことを可能にする。
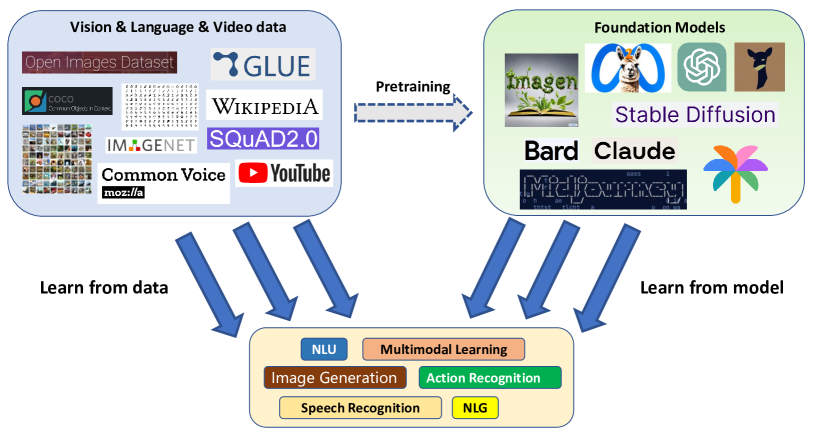
Foundation models (FM) have demonstrated remarkable performance across a wide range of tasks (especially in the fields of natural language processing and computer vision), primarily attributed to their ability to comprehend instructions and access extensive, high-quality data. This not only showcases their current effectiveness but also sets a promising trajectory towards the development of artificial general intelligence. Unfortunately, due to multiple constraints, the raw data of the model used for large model training are often inaccessible, so the use of end-to-end models for downstream tasks has become a new research trend, which we call Learn From Model (LFM) in this article. LFM focuses on the research, modification, and design of FM based on the model interface, so as to better understand the model structure and weights (in a black box environment), and to generalize the model to downstream tasks. The study of LFM techniques can be broadly categorized into five major areas: model tuning, model distillation, model reuse, meta learning and model editing. Each category encompasses a repertoire of methods and strategies that aim to enhance the capabilities and performance of FM. This paper gives a comprehensive review of the current methods based on FM from the perspective of LFM, in order to help readers better understand the current research status and ideas. To conclude, we summarize the survey by highlighting several critical areas for future exploration and addressing open issues that require further attention from the research community. The relevant papers we investigated in this article can be accessed at https://github.com/ruthless-man/Awesome-Learn-from-Model
研究の動機と目的
- Define the Learn From Model (LFM) パラダイムとその動機を定義する。
- LFM の下で FM-based 手法を5つの領域(調整、蒸留、再利用、メタ学習、編集)にわたって整理・分析する。
- 下流タスクに対する LFM の長所・制約・実務上の考慮事項を明らかにする。
- 研究と実務を指針づけるための LFM の今後の方向性と未解決課題を特定する。
提案手法
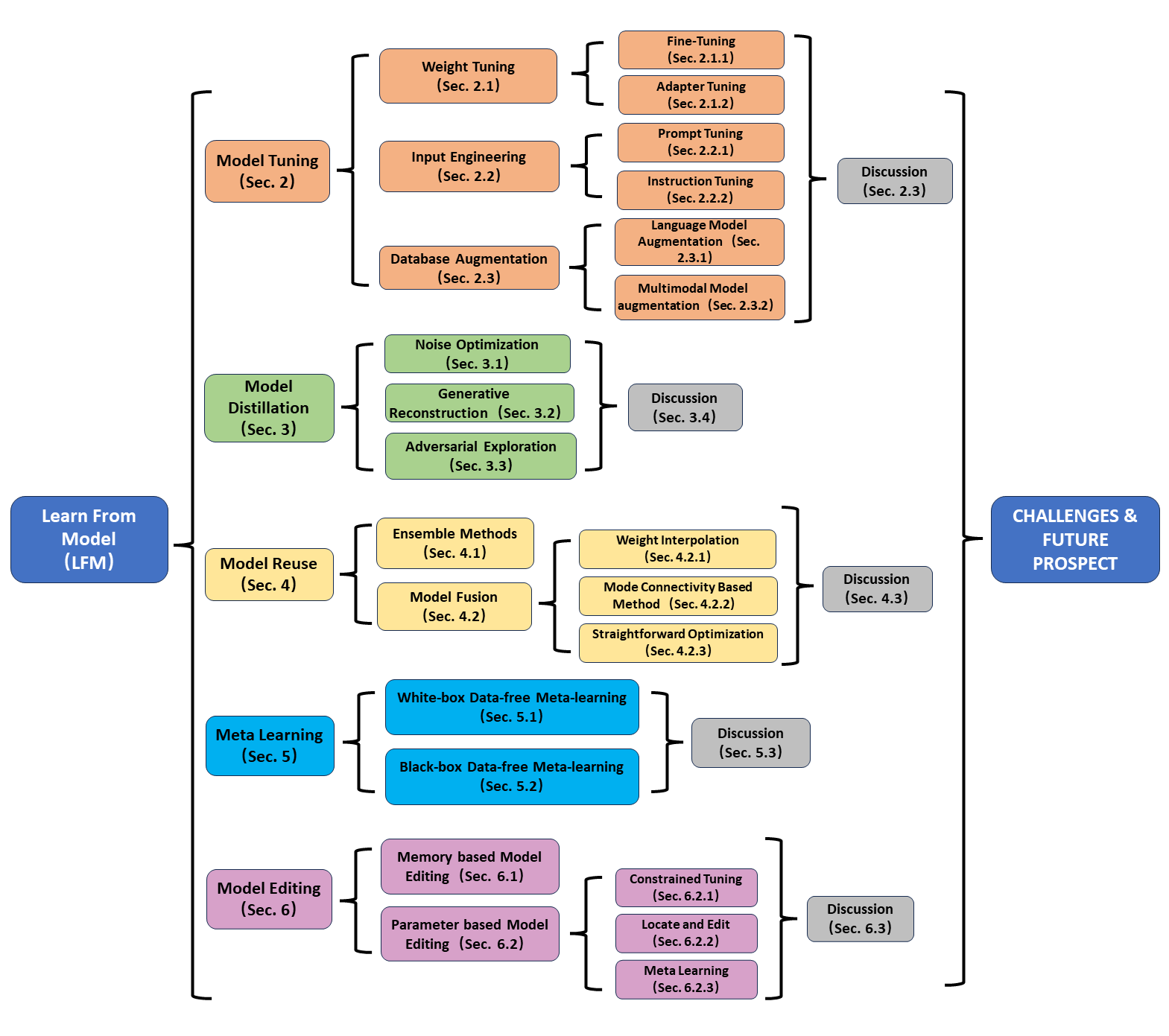
- 5つの中核領域(モデル調整、モデル蒸留、モデル再利用、メタ学習、モデル編集)を含む、階層的な LFM タクソノミーを提示する。
- 各領域の代表的な手法を要約する(例:ファインチューニング、アダプター、プロンプト調整、指示調整、検索/拡張、データフリー蒸留など)。
- LFM を従来のデータからの学習と対比し、データのプライバシー、コスト、知識移転の観点を強調する。
- データアクセスの制約、計算量、モデルの安定性といった課題を論じ、損失設計、メモリ検索のトレードオフ、特定用途向けの検索指標の提案方向性を示す。
- 今後の LFM アプリケーションと未解決課題に対する未来志向の展望を総合し、さらなる研究を促進する。
実験結果
リサーチクエスチョン
- RQ1What constitutes Learn From Model and how does it differ from learning from data?
- RQ2What are the main categories of LFM methods and their respective trade-offs?
- RQ3What are the key open issues and future directions for LFM in foundation models?
主な発見
- LFM offers a systematic framework to study foundation models via their interfaces, enabling adaptation with less data and computation than full retraining.
- The survey consolidates five LFM paradigms—model tuning, distillation, reuse, meta-learning, and editing—providing a comprehensive taxonomy and method overview.
- Adapter-based and prompt-based tuning can achieve competitive performance with fewer trainable parameters and reduced risk of overfitting.
- External knowledge via database augmentation and multimodal retrieval enhances model capabilities and up-to-date knowledge without full model retraining.
- The paper discusses future directions including loss function design, retrieval-memory vs. efficiency balance, and the need for tailored retrieval metrics.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。