[論文レビュー] Learning gain differences between ChatGPT and human tutor generated algebra hints
本研究は、ChatGPT生成の代数ヒントと人間の家庭教師ヒントからの学習増分を比較し、人間のヒントの方が高い増分を生み出すこと、また約30%のChatGPTヒントが品質のため却下されたことを示した。
Large Language Models (LLMs), such as ChatGPT, are quickly advancing AI to the frontiers of practical consumer use and leading industries to re-evaluate how they allocate resources for content production. Authoring of open educational resources and hint content within adaptive tutoring systems is labor intensive. Should LLMs like ChatGPT produce educational content on par with human-authored content, the implications would be significant for further scaling of computer tutoring system approaches. In this paper, we conduct the first learning gain evaluation of ChatGPT by comparing the efficacy of its hints with hints authored by human tutors with 77 participants across two algebra topic areas, Elementary Algebra and Intermediate Algebra. We find that 70% of hints produced by ChatGPT passed our manual quality checks and that both human and ChatGPT conditions produced positive learning gains. However, gains were only statistically significant for human tutor created hints. Learning gains from human-created hints were substantially and statistically significantly higher than ChatGPT hints in both topic areas, though ChatGPT participants in the Intermediate Algebra experiment were near ceiling and not even with the control at pre-test. We discuss the limitations of our study and suggest several future directions for the field. Problem and hint content used in the experiment is provided for replicability.
研究の動機と目的
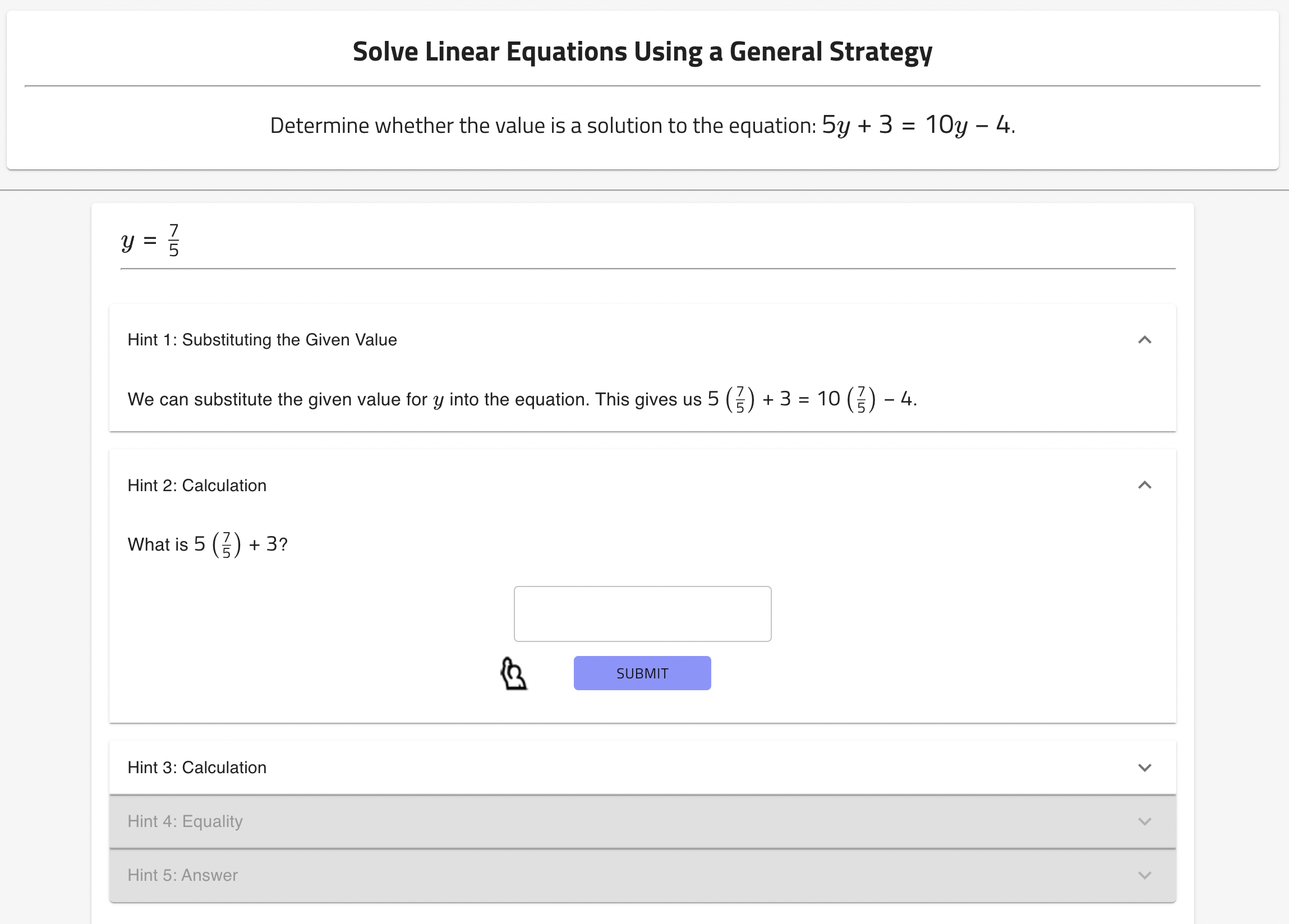
- ChatGPT生成のヒントが代数の学習増分を促進する際に人間の家庭教師のヒントと等しくなり得るかを評価する。
- 代数問題に対するChatGPT生成のヒントの品質と信頼性を評価する。
- LLMベースのチュータリングヒントにおける将来の研究のために再現可能な内容と方法を提供する。
提案手法
- 小学校レベルと中級代数のレッスンを用いた二択の2x2実験デザイン。
- ChatGPT生成のヒントは、2022年12月15日モデルを用い、OATutorコンテンツの問題プロンプトを使用して生成された。
- OpenStax由来のコンテンツを用いた対照条件として、手動の人間チューターヒント。
- 各参加者につき、3問のプレテスト、5問の習得段階、3問のポストテスト(プレテストとポストテストは同じ問題)。
- 品質チェック: 正解、正しい解法の手順、適切でない表現がないこと。いずれかのチェックが失敗した場合は不適合とする。

実験結果
リサーチクエスチョン
- RQ1RQ1: ChatGPTは低品質のヒントをどのくらいの頻度で生成するか?
- RQ2RQ2: ChatGPTのヒントは学習増分を生み出すか?
- RQ3RQ3: 学習増分において、ChatGPTのヒントは人間のチューターヒントとどのように比較されるか?
主な発見
| Textbook Level | Condition | N | Avg. Time | Hints Requested | Learning Gain | Avg. Pre-test | Avg. Post-test |
|---|---|---|---|---|---|---|---|
| Elementary | Control | 19 | 08:16 | 132 | 24.63% | 59.68% | 84.32% |
| Elementary | Experiment | 21 | 09:01 | 30 | 11.14% | 74.67% | 85.81% |
| Intermediate | Control | 17 | 12:53 | 150 | 23.65% | 50.94% | 74.59% |
| Intermediate | Experiment | 20 | 11:06 | 57 | 1.7% | 80.05% | 81.75% |
- 全ての条件で学習増分が見られたが、統計的有意性は手動ヒント条件でのみ達成された。
- 手動ヒントは、ElementaryおよびIntermediate Algebraの両方でChatGPTヒントより高い学習増分をもたらした。
- Intermediate Algebraでは、ChatGPT参加者はプレテスト時点で天井付近(約80%)から始まり、ポストテストの増分とは有意差がなかった。対照群は両科目でプレテストと有意に異なるままであった。
- ChatGPTヒントは品質問題(回答が誤っている、手順が誤っている)により30%の却下率だった。
- 所要時間は条件間で類似していたが、ChatGPTは品質フィルタリングされた限られた回答のため、ヒントの数が少なくて済んだ。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。